
はじめに
こんにちは!Sreake事業部 志羅山です。今年3月に3-shakeに入社し、長野県からリモートで仕事をしています(東京にも定期的に行ってます)。
最近、とあるお客様環境におけるECS(AWSのフルマネージド型コンテナオーケストレーションサービス)の利用方針を整備する中で、ECSの可用性に関する設計要素について調査・整理する機会がありました。今回この記事ではその内容を紹介したいと思います。
整理してみて感じたこととして、「思ったよりも考えることが多く、やや複雑で奥深い」という印象を受けました。同じように感じている方にとって参考になれば幸いです。
当記事の目的と書くこと
この記事は「ECSの可用性に関する設計要素や考慮事項の体系がややぼんやりしている」という読者の方に「全体のイメージが何となくつかめた」と感じてもらえることを目的としています。
そのために、「ECSの可用性設計要素」というテーマを
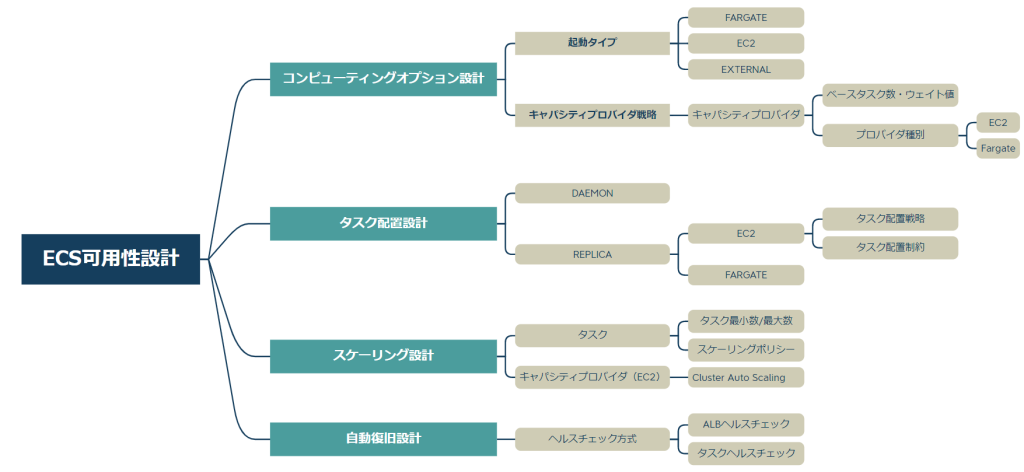
- コンピューティングオプション設計
- タスク配置設計
- スケーリング設計
- 自動復旧設計
の4つの軸に分解し、各要素について検討していきます。
尚、ECSの基本的な知識については一定のレベルで理解されていることを前提とし、タスクやサービスといった用語の説明は最小限に留めるものとします。
各設計要素
コンピューティングオプション設計
AWSのデベロッパーガイドによれば、ECSのレイヤは
- キャパシティ:コンテナが稼働するインフラストラクチャ
- コントローラ:コンテナ上で実行されるアプリケーションの管理コンポーネント
- プロビジョニング:AWS CDKやAWS Copilotなどのデプロイ管理ツール
の3つで構成されており、1番目の「キャパシティ」に関する設定は、AWSマネジメントコンソール上では「コンピューティングオプション」と呼称されています。
ここではそのコンピューティングオプションの設計について整理します。
コンピューティングオプションとは、つまりは「タスクをキャパシティにどう起動するか?」についての設定ですが、「キャパシティプロバイダ戦略」と「起動タイプ」の2つに大別されます。
起動タイプ
タスクを起動するキャパシティ種別(FARGATE, EC2, EXTERNAL)だけを指定する方式です。
EC2を指定する場合、あらかじめECSエージェントをインストールしてECSクラスタに登録したEC2インスタンスにタスクが起動しますが、起動タイプ方式ではこのインスタンスの水平スケーリングを管理することができない点に注意が必要です。水平スケーリングを管理したい場合はキャパシティプロバイダ戦略を利用するとよいでしょう。
ちなみに、FARGATEの場合は、タスク起動先のAZはECSサービスに紐づいているサブネットのAZに自動分散されます。簡易的な検証利用や、Fargate利用で特にコスト戦略が無い場合はこちらがいいかと思います。
キャパシティプロバイダ戦略
「どの種類のキャパシティにどれくらいタスクを起動する」という細かい戦略を指定する方式です。前述の起動タイプ方式に対して、細かいチューニングやスケーリング管理ができるので、商用利用はこちらが向いているでしょう。
キャパシティプロバイダ戦略は、以下の3要素で構成されています。
- キャパシティプロバイダ:Fargate or EC2
- ベース:そのプロバイダに起動する最小タスク数
- 複数のキャパシティプロバイダを設定している場合(例えば、FARGATEとFARGATE_SPOT)、ベースはいずれかのキャパシティプロバイダにしか設定できません。
- タスクの起動時には、まずベースが設定されているプロバイダにベース分のタスクが起動され、それ以降はウェイト設定に従ってタスクが起動されます。
- ウェイト:タスク起動数の比重
Fargateキャパシティプロバイダは、FARGATEかFARGATE_SPOTのみ選択可能で、それぞれのベース・ウェイトを設定します(タスクのAZ分散が自動で行われる点は起動タイプと同様です)。このオプションによって、例えばタスクの何割かをFARGATE_SPOTに寄せることで、全体のコスト効率と可用性のバランスを調整することができます。
EC2キャパシティプロバイダは、Auto Scaling Group(以下ASG。専用が推奨)を紐づけ、そのASGで定義されたEC2インスタンスをキャパシティとして利用します。
このオプションの使い方としては、例えばキャパシティプロバイダ戦略1つに対してAZ1,AZ2,AZ3で起動するキャパシティプロバイダ3つを紐づけ、それぞれのウェイトを同じにすることで、タスクが起動するAZを分散させるといった使い方があります。
なお、「キャパシティをEC2にするかFargateにするか?」という論点については、可用性以外のコスト等の要素も多分に含まれるため、本記事では割愛します。
タスク配置設計
コンピューティングオプション設計を経てタスクを起動するキャパシティの利用方式が決まったら、次は「そこにどうタスクを起動するか?」を考えていきます。
サービスタイプ
タスクの配置管理方式であるサービスタイプは、以下2種類が存在します。
| サービスタイプ | 挙動 | 対応するコンピューティングオプション |
|---|---|---|
| REPLICA | クラスタ全体で必要なタスクの数を配置・維持する | どのタイプのキャパシティプロバイダ戦略・起動タイプでも利用可 |
| DAEMON | クラスタ内のアクティブなコンテナインスタンスごとに、指定したタスクが1:1で起動するように配置・維持する | 起動タイプEC2/EXTERNALでのみ利用可 |
DAEMONは、例えば「各コンテナインスタンスのログをCloudWatchで収集したい」という場合に、各コンテナインスタンスごとに1つずつCloudWatchエージェントのコンテナを起動する、といったような目的で使用します。
REPLICAのスケジューリング方式
REPLICAは、クラスタ全体で必要なタスク数を維持する方式ですが、EC2に起動する場合は「複数のタスクを複数のEC2インスタンスにどのように起動させたいか?」も指定することができます(Fargateの場合はAZ自動分散されるので考慮不要です)。
具体的には、タスク分散方式を定義する配置戦略と、タスクをスケジュールするインスタンスを限定する配置制約の2つが検討要素となります。
AWSマネジメントコンソール上では、あらかじめ定義されたテンプレート4つに加え、利用者独自に配置戦略と配置制約を組み合わせる「カスタム」が選択できますが、推奨されない配置戦略・配置制約の組み合わせも存在するため、必要に応じて開発者ガイドを参照しましょう。
| 配置テンプレート名 | AZ間分散 | コンテナインスタンス分散方式 |
|---|---|---|
| AZバランススプレッド | する | 各インスタンスに均等にタスクを配置する |
| AZバランスビンパック | する | 全コンテナインスタンスの中でリソースに最も余裕があるインスタンスからタスクを配置していく |
| ビンパック | しない | 同上 |
| ホストごとに1つのタスク | しない | コンテナインスタンスごとに1つのタスクのみを配置する |
| カスタム | 設定に依存 | 設定に依存する。 Spreadをインスタンスタイプ単位で分散したり、binpackにCPUメトリクスを指定したり、起動するコンテナインスタンスを絞る等の複数のルールを組み合わせることが可能 |
スケーリング設計
タスクの起動方式が決まったので、次は負荷などに応じた水平スケーリングの方式を決めていきます。
ECSにおけるスケーリング方式は、「タスクのスケーリング」と「キャパシティプロバイダ(EC2)のスケーリング」の2軸で考えていきます。
タスクのスケーリング設計
この設定はECSサービスごとに任意で設定でき、タスクのスケーリングをサービス全体のメトリクスや特定のアラームを基準に自動化することができます。
設定要素はタスク最小数・タスク最大数、そしてスケーリングポリシーの3つとなります。
スケーリングポリシーは以下2つから選択することになりますが、ステップスケーリングは最適化の難易度が高いため、細かい要件がなければターゲット追跡がよいでしょう。
- ターゲット追跡:サービス全体のメトリクスが目標値に収束するようにタスクをスケールする
- ステップスケーリング:メトリクス値やCloudWatchアラームをトリガーに、各段階ごとにタスクをスケールする
キャパシティプロバイダのスケーリング設計
この項目は、キャパシティプロバイダにEC2を使用している場合に検討します。
EC2キャパシティプロバイダには作成時にASGを紐づける必要があり、EC2インスタンスはこのASGの設定に基づいてスケーリングされます。
このASGのDesired Capacityは管理者がチューニングすることもできますが、タスクのスケーリングとEC2インスタンスのスケーリングを別々に管理するのは手間なので、インスタンスのスケーリング管理はECS Cluster Auto Scaling(CAS)を有効化して自動化するのがよいでしょう。
このCASによるマネージドスケーリングを有効化すると、サービス内のタスクの増減が発生した際、あらかじめ設定したキャパシティメトリクスに収束するようにECSがAutoScalingグループのDesiredCapacityを自動で変更してくれます。
自動復旧設計
ここまでで、タスクの増減によってどのようにECSのインフラストラクチャをスケーリングさせるかが決まりました。最後に、肝心のタスクの回復性をどのように担保するか?という点について考えます。
ECSの自動復旧の基本的な仕組み
ECSは、ヘルスチェックの結果によってタスクが「ステータスがunhealthyである」と判定された場合、そのタスクをdrainingし新しいタスクに置き換える処理を行います。
このヘルスチェックは、「ELBヘルスチェック」と「ECSコンテナヘルスチェック」の2種類が存在します。
いずれのヘルスチェックも、処理自体はタスクのプロビジョニング後すぐに開始されますが、開始期間(タスクが起動処理を行っているの間の猶予時間設定)の間はヘルスチェック処理結果はタスクのステータスの集計に反映されず、ステータスはunknownのままとなります。
ちなみに、ECSタスク内のコンテナはbool型のessentialというパラメータを持っており、この属性がtrueであるコンテナが異常終了した場合も、タスク全体が終了し、置き換え処理が走ります(sidecarコンテナのようにタスク内で補助的に動くコンテナにはfalseを設定することで、sidecarコンテナの異常終了がアプリケーションに影響を与えないようにすることもできます)。
ELBヘルスチェック
ELBターゲットグループ内のタスクに対するELBからのHTTP/HTTPSヘルスチェックです。
ELBヘルスチェックの判定は内部的にECSに連携されるようになっており、unhealthyと判定されたタスクはECSによる置き換え処理の対象となります。
チューニングポイントはECSサービス側の「ヘルスチェックの猶予期間(healthCheckGracePeriodSeconds)」です。この設定によって、ELBのヘルスチェック結果を無視する時間を設定できます。
この設定は、
- 新しいタスクが起動してヘルスチェックに合格するようになるまでの一定時間、ELBヘルスチェックを無視したい
- タスクにログインして切り分けを行う間、ELBヘルスチェックを無視してタスクが置き換えられないようにしたい
といったニーズに応じて調整します。
コンテナヘルスチェック
ELBヘルスチェックはHTTP/HTTPSリクエストのレスポンスでしか判定できませんが、コンテナヘルスチェックでは各タスクの各コンテナごとに個別に設定したコマンドでヘルスチェックを行うことができます。
同一タスク内の特定のコンテナのヘルスチェック結果を他のコンテナの起動条件に指定したい(依存関係を設定したい)といった場合は、このコンテナヘルスチェックを利用します。
尚、ELBヘルスチェックとコンテナヘルスチェックは併用が好ましいですが、併用する場合、ELBヘルスチェックの猶予期間や判定が常に優先されます(例えば、猶予期間中にコンテナヘルスチェックが失敗してもタスクの置き換えは発生しません)。
サマリ・全体像
ここまでで整理した内容から、設計方針の見解を示してみます。ここから個別要件を取り込んでカスタマイズしていくのが良いのではないかと思います。
- コンピューティングオプションは商用利用の場合は基本的にキャパシティプロバイダ方式を選択する(可用性やコストの要件がゆるい場合は起動タイプ方式も可)
- 配置設計(サービスタイプ)は基本的にはREPLICAで、配置テンプレートはAZ分散・インスタンス分散型が標準的でよい。
- スケーリング設計は、
- タスクのスケーリング設定はターゲット追跡型で設定する(ステップスケーリングは設定の最適化が高度)
- EC2キャパシティプロバイダ戦略を利用する場合、EC2インスタンスのスケール設定はマネージドスケーリングを利用し、タスクのスケーリングのみチューニング対象にする
- 自動復旧設計は、ELBヘルスチェックとタスクヘルスチェックを併用することを推奨する。併用にあたっては併用時の挙動に注意すること。
ECSの可用性設計を検討している方の参考になれば幸いです。