
自己紹介
小林
インターン生のの小林です。大学では、ネットワーク系の研究を行っています。もともとセキュリティやネットワークに興味があり、SREやインフラ領域のスキル向上になると思い、本インターンに参加しました。
中村
インターン生の中村です。低レイヤーに興味があり、普段はOSやコンパイラについて学んでいます。その中で、特にeBPFやXDPといったLinux Kernelのネットワーク技術が面白いと感じたため本インターンに参加しました。
はじめに
はじめまして、スリーシェイクのSreake事業部インターン生の小林と中村です。
私たちは、SRE技術の調査と研究を行う目的で2024年3月18日~3月29日に開催された2週間のインターンに参加しました。
私たちはどちらもインターン参加前からeBPFに興味があったため、eBPFを使ったプロダクトの調査をする方向性でテーマを考え、eBPFを使ってネットワークやセキュリティ、オブザーバビリティを提供するツールであるCiliumについて調査しました。また、GKE Dataplane V2はCiliumをベースに実装されていることから、GKE Dataplane V2についてもGKE Dataplane V1と比較しながら調査を行いました。
以降で、その成果を記述します。
※ Google Cloudでは、”以前の GKE Dataplane”としか記述がありませんが、本ブログでは、便宜上、”以前のGKE Dataplane”を“GKE Dataplane V1”と呼びます。
要約
このインターンでは、Ciliumのkube-proxy replacement及びGKE Dataplane V1・V2の違いについての調査を行いました。
Ciliumでは、kube-proxyをeBPFで置き換える取り組みが行われました。これにより、動的なネットワーク変更時のルール書き換えのオーバーヘッドが軽減され、大規模クラスターでも効率的に動作するようになりました。また、GoogleもGKE Dataplane V2では、Ciliumを採用しています。これにより、GKE Dataplane V2では、Kubernetes NetworkPolicyが常に有効になり、ネットワークポリシーロギングが組み込まれます。ただし、GKE Dataplane V2ではCiliumのすべての機能をサポートしているわけではなく、Cilium NetworkPolicyなどの一部の機能は使用できません。
さらに、実際にGKE Dataplane V1とV2でクラスターを構築し、ツール用いて検証を行った結果、それぞれiptablesとeBPFでDNATを行っていることがわかりました。その結果をもとに、kube-proxyやCiliumのソースコードを読むことで、V1とV2でのDNATの実装について調査しました。
前提知識
GKE(Google Kubernetes Engine)
Googleが提供するマネージドKubernetesサービスのことで、コンテナ化されたアプリケーションのデプロイと運用を大規模に行うために使用することができます。
GKEでは、コントロールプレーンとシステムコンポーネントがGoogleによって管理されているため、Kubernetes環境の構築・運用にコストをかける必要がなくなり、サービスの開発に専念することができます。
CNI(Container Network Interface)
CNIでは、コンテナ作成時のネットワーク接続とコンテナ削除時の割り当てられたリソース削除に関する仕様を定義しています。そして、実際にこの仕様に則り、実装が行われたネットワークプラグインを使うことで、Kubernetesでコンテナ間の通信が可能になります。
Cilium
Ciliumは、Kubernetesなどのクラウドネイティブ環境にネットワーク、セキュリティおよびオブザーバビリティを提供するオープンソースプロジェクトであり、Kubernetes CNIプラグインとして動作します。
CiliumではeBPFを使用することで、セキュリティやオブザーバビリティ、ネットワークの制御ロジックを Linuxカーネルに動的に挿入しています。
Ciliumのkube-proxy replacementについて
次に、Ciliumプロジェクトで行われたkube-proxyの置き換えについて紹介します。
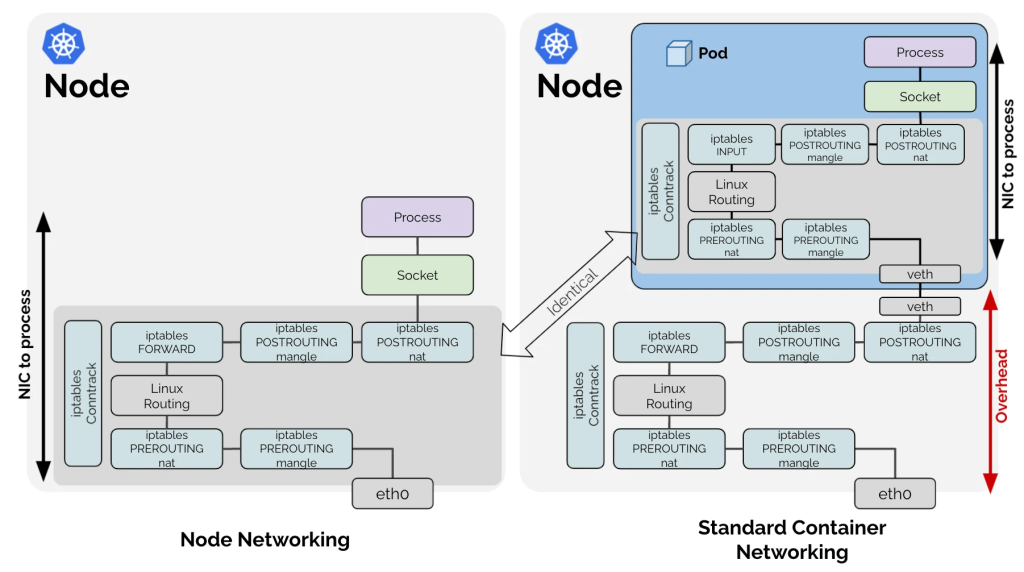
Kubernetesにはkube-proxyと呼ばれるコンポーネントがあります。これは、クラスター内の各ノードで実行されるネットワークプロキシとしての役割を持ち、iptablesを用いて実装されています。iptablesコマンドを利用すると、パケットフィルタリングやNAT機能を持つNetfilterを操作することができます。
また、KubernetesではCNIを通してどのネットワーク実装を利用するかユーザが選べるようになっています。Ciliumはそのひとつです。多くのCNIプラグインはKubernetesにおける L3/L4 のネットワークポリシーを実装するためにiptablesを利用しています。
Kubernetesでは、PodとIPアドレスは動的に追加・削除され、その度にiptablesのルールがすべて書き換えられます。そのため、Kubernetesクラスターの規模が大きい場合、性能に悪影響を及ぼします。
さらに、iptablesのルールの検索にはO(N)の計算量がかかるため、ルールの数が増えると所要時間が増えていきます。
{kind=link}
この問題を解決するために、CiliumではeBPFを活用してkube-proxyを置き換える取り組みが行われました。
https://cilium.io/blog/2019/08/20/cilium-16/#kubeproxy-removal
具体的には、eBPFハッシュテーブルMapと呼ばれるeBPFプログラムがデータを保持するためのデータ構造を使います。このハッシュテーブルをネットワークポリシールールやコネクションの追跡、ロードバランサーのバックエンドのテーブル保存のために使用することで、iptablesのルールを置き換えています。これによって、要素の追加と探索を概ねO(1)の計算量で行うことが可能です。
{kind=link}
kube-proxyを置き換えたことによる性能改善については、Ciliumの公式ブログにベンチマークがまとめられています。
https://cilium.io/blog/2021/05/11/cni-benchmark/#ebpfhostrouting
さらに、GoogleはGKE Dataplane V2にCiliumを採用しています。次の章では、Dataplane V1とV2の違いについて説明します。
https://cilium.io/blog/2020/08/19/google-chooses-cilium-for-gke-networking/
GKE Dataplane V1とV2の違い
ドキュメントからわかったこと
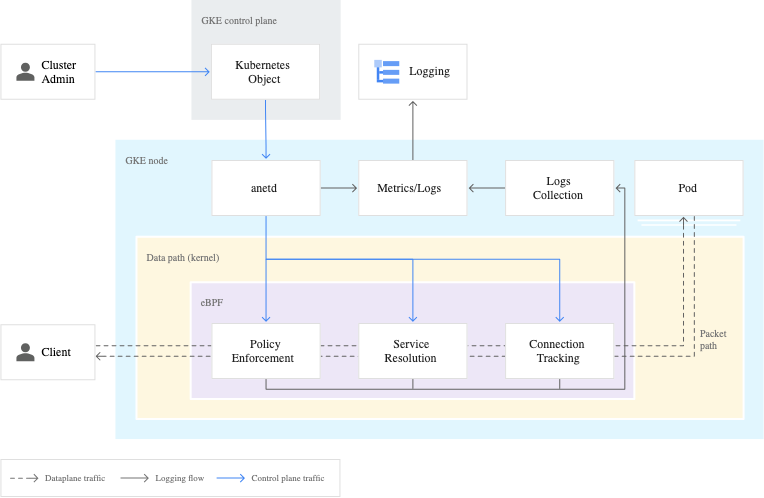
Kubernetes NetworkPolicyを有効にするために、GKE Dataplane V1ではCalicoを、GKE Dataplane V2ではCiliumを用いて実装されています。
https://cloud.google.com/kubernetes-engine/docs/concepts/dataplane-v2#network-policy
{kind=link}
GKE Dataplane V2は以前のDataplaneと比較して、以下のような側面で利点があります。
- スケーラビリティ:
kube-proxyを使用せず、CiliumがServiceを管理します。つまり、iptablesに依存しないため、パフォーマンスが向上します。 - セキュリティ:
V2のクラスターではCiliumが標準搭載されているため、Kubernetes NetworkPolicyが常に有効になっています。そのため、NetworkPolicyを適用するために、ユーザが新たにCNIをインストールして管理する必要がありません。 - 運用:
V2でクラスターを作成すると、ネットワークポリシーロギングが組み込まれます。クラスターでCRDによって定義されたNetworkLoggingのオブジェクトを構成すると、Podによっていつ接続が許可または拒否されたかを確認できます。
GKE Dataplane V2の詳細については、以下の公式ドキュメントをご覧ください。 https://cloud.google.com/kubernetes-engine/docs/concepts/dataplane-v2
また、GKE Dataplane V2ではCiliumのすべての機能をサポートしているわけではなく、Cilium NetworkPolicyなどの一部の機能は使用できません。詳細については、GKE Dataplane V2の公式ドキュメントの制限事項をご覧ください。
実際に構築
GKE Dataplane V1とGKE Dataplane V2でどのように違いがあるのか、実際にクラスターを構築して検証しました。今回は、Cloud Shellでコマンドを実行することで、クラスターを作成しています。
GKE Dataplane V1
まず、GKE Dataplane V1を使用するクラスターを作成します。今回は、—enable-network-policy で Calico Kubernetes ネットワーク ポリシーを有効にしています。
# Cloud Shellで"gke-dataplane-v1"というクラスターを作成します
$ gcloud container clusters create gke-dataplane-v1 --zone=asia-northeast1-a --enable-network-policyクラスターが作成できたら、以下のようにしてDeploymentとServiceを作成し、外部からアクセスできることを確認します。今回は kubectl createやkubectl expose で Deployment や Serviceを作成していますが、 これらのコマンドに--dry-run=client -o yaml オプションをつけることで、マニフェストファイルを確認することができます。
# nginxのPodを3つ作るDeploymentを作成
$ kubectl create deployment nginx-deployment --image=nginx --replicas=3
# 外部に公開するためのServiceを作成
$ kubectl expose deployment nginx-deployment --type=LoadBalancer --name=nginx --port=80 --target-port=80
# 3ノードでnginxポッドが3つ動いており、service/nginxにEXTERNAL-IPが付与されていることを確認
$ kubectl get pods,deployment,svc -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/nginx-deployment-66fb7f764c-ltkzj 1/1 Running 0 33m 10.32.1.11 gke-gke-dataplane-v1-default-pool-c61696b8-8esn <none> <none>
pod/nginx-deployment-66fb7f764c-mlm2g 1/1 Running 0 33m 10.32.2.8 gke-gke-dataplane-v1-default-pool-c61696b8-il5v <none> <none>
pod/nginx-deployment-66fb7f764c-skbxp 1/1 Running 0 33m 10.32.3.13 gke-gke-dataplane-v1-default-pool-c61696b8-e0x8 <none> <none>
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment.apps/nginx-deployment 3/3 3 3 33m nginx nginx app=nginx-deployment
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.36.0.1 <none> 443/TCP 6d5h <none>
service/nginx LoadBalancer 10.36.4.187 35.221.94.105 80:31254/TCP 26m app=nginx-deployment
# EXTERNAL-IPにアクセスする
$ curl 35.221.94.105
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
~ 省略 ~次に、kube-system NamespaceのPodを見てみると、kube-proxyとCalicoのPodが作られていることが確認できます。CalicoのPodはNetworkPolicyを適用するために必要なコンポーネントであるため、クラスター作成時にCalico NetworkPolicyを無効にしていると作成されませんが、Pod へのIPアドレスの割り当てやNode間のルーティングなどはCalicoによって行われます。
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-node-2svmd 1/1 Running 0 25h
calico-node-69d7r 1/1 Running 0 25h
calico-node-7hfm2 1/1 Running 0 25h
calico-node-vertical-autoscaler-6446d6bc5c-l474g 1/1 Running 0 25h
calico-typha-94876c957-6sk2w 1/1 Running 0 25h
calico-typha-94876c957-v7m24 1/1 Running 0 25h
calico-typha-horizontal-autoscaler-5b57b69bc5-8qv2g 1/1 Running 0 25h
calico-typha-vertical-autoscaler-fcc7f69d-54b8s 1/1 Running 0 25h
event-exporter-gke-5b8bcb44f7-fbr47 2/2 Running 0 25h
fluentbit-gke-lc56d 2/2 Running 0 25h
fluentbit-gke-th79k 2/2 Running 0 25h
fluentbit-gke-wdlkt 2/2 Running 0 25h
gke-metrics-agent-4fpml 2/2 Running 0 25h
gke-metrics-agent-4qn2t 2/2 Running 0 25h
gke-metrics-agent-bghxr 2/2 Running 0 25h
ip-masq-agent-dqqt7 1/1 Running 0 25h
ip-masq-agent-f5nk9 1/1 Running 0 25h
ip-masq-agent-fs2ts 1/1 Running 0 25h
konnectivity-agent-6c877c9f98-8lm6w 1/1 Running 0 25h
konnectivity-agent-6c877c9f98-qds9c 1/1 Running 0 25h
konnectivity-agent-6c877c9f98-tp69t 1/1 Running 0 25h
konnectivity-agent-autoscaler-5d9dbcc6d8-wdzpv 1/1 Running 0 25h
kube-dns-6f9b8847ff-ncwx2 4/4 Running 0 25h
kube-dns-6f9b8847ff-z5qxw 4/4 Running 0 25h
kube-dns-autoscaler-84b8db4dc7-4k9dl 1/1 Running 0 25h
kube-proxy-gke-gke-dataplane-v1-default-pool-c61696b8-8esn 1/1 Running 0 25h
kube-proxy-gke-gke-dataplane-v1-default-pool-c61696b8-e0x8 1/1 Running 0 25h
kube-proxy-gke-gke-dataplane-v1-default-pool-c61696b8-il5v 1/1 Running 0 25h
l7-default-backend-cf7cdc6f6-2dgqc 1/1 Running 0 25h
metrics-server-v0.5.2-8fb865474-ndz58 2/2 Running 0 25h
pdcsi-node-8xvsp 2/2 Running 0 25h
pdcsi-node-dwfxz 2/2 Running 0 25h
pdcsi-node-x46dm 2/2 Running 0 25h次に、kube-proxyがどうやってPod間通信を可能にしているのか確認するために、iptablesのルールを見てみます。GKEのワーカーノードもその実体はGCE(Google Compute Engine)というVMであり、その上でPodを動かしています。そのため、ワーカーノードであるVMにsshでアクセスし、iptablesのルールを出力します。
# ワーカーノードを確認
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gke-gke-dataplane-v1-default-pool-c61696b8-8esn Ready <none> 7h28m v1.27.8-gke.1067004
gke-gke-dataplane-v1-default-pool-c61696b8-e0x8 Ready <none> 7h35m v1.27.8-gke.1067004
gke-gke-dataplane-v1-default-pool-c61696b8-il5v Ready <none> 7h32m v1.27.8-gke.1067004
# gke-gke-dataplane-v1-default-pool-c61696b8-8esn にsshでアクセスする
$ gcloud compute ssh --project "sreake-intern" --zone "asia-northeast1-a" "gke-gke-dataplane-v1-default-pool-c61696b8-8esn"
# iptablesのルールを表示する(-t nat:NATテーブルを指定, -L:リスト形式, -n:IPアドレスとポート番号を数値で出力 )
kobayashi@gke-gke-dataplane-v1-default-pool-c61696b8-8esn ~ $ sudo iptables -t nat -L -n
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
cali-PREROUTING all -- 0.0.0.0/0 0.0.0.0/0 /* cali:6gwbT8clXdHdC1b1 */
~ 省略 ~NATテーブルのみでもたくさんのルールが表示されました。そこで、PodやServiceを作る前後でどのようにiptablesのルールが変わるのかを確かめました。すると、Podが作られたタイミングではなく、Serviceが作られたタイミングでNATルールが追加されました。
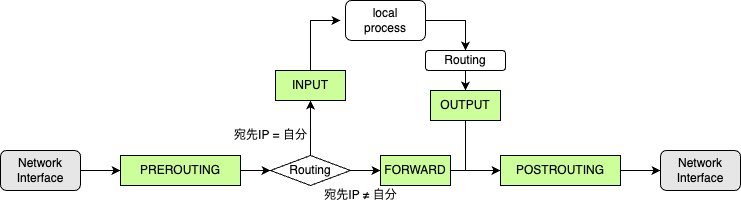
iptablesのルールを見ていく前に、iptablesのチェインについて少しだけ説明しておきます。
チェインには、Netfilterのフックによって呼び出されるベースチェインと、ほかのチェインから呼び出されるレギュラーチェインの2種類があります。ベースチェインでは prerouting, input, forward, output, postrouting の5つが定義されており、これらのチェインから他のレギュラーチェインにジャンプしたり、ルールを参照しながら、パケットのフィルタリングやNATを行います。5つのベースチェインの違いは、下の表に示します。また、これらのチェインが呼び出されるタイミングを簡素化して書いたものが下の図になります。
Netfilterフックの詳細については、以下のドキュメントをご覧ください。
https://wiki.nftables.org/wiki-nftables/index.php/Netfilter_hooks
| prerouting | パケット受信時にルールを参照する |
| input | 自分宛のパケットの場合にルールを参照する |
| forward | 転送するパケットの場合にルールを参照する |
| output | 自分が生成したパケットに対してルールを参照する |
| postrouting | パケット送信時にルールを参照する |
Serviceの追加前後でのiptablesの差分を示します。iptablesで負荷分散とDNAT(Destination NAT: 宛先IPアドレスの変更)を行うルールが新たに追加されています。
+Chain KUBE-EXT-2CMXP7HKUVJN7L6M (2 references)
+target prot opt source destination
+KUBE-MARK-MASQ all -- 0.0.0.0/0 0.0.0.0/0 /* masquerade traffic for default/nginx external destinations */
+KUBE-SVC-2CMXP7HKUVJN7L6M all -- 0.0.0.0/0 0.0.0.0/0
Chain KUBE-NODEPORTS (1 references)
target prot opt source destination
+KUBE-EXT-2CMXP7HKUVJN7L6M tcp -- 0.0.0.0/0 0.0.0.0/0 /* default/nginx */ tcp dpt:30415
KUBE-EXT-XP4WJ6VSLGWALMW5 tcp -- 0.0.0.0/0 0.0.0.0/0 /* kube-system/default-http-backend:http */ tcp dpt:30986
+Chain KUBE-SEP-44W4V6DCT4JUKJOF (1 references) [DNAT]
+target prot opt source destination
+KUBE-MARK-MASQ all -- 10.32.3.14 0.0.0.0/0 /* default/nginx */
+DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 /* default/nginx */ tcp to:10.32.3.14:80
+Chain KUBE-SEP-DZECBLFBK3Q7X4I5 (1 references) [DNAT]
+target prot opt source destination
+KUBE-MARK-MASQ all -- 10.32.1.12 0.0.0.0/0 /* default/nginx */
+DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 /* default/nginx */ tcp to:10.32.1.12:80
+Chain KUBE-SEP-FLZ7GUCVWEOYSVXC (1 references) [DNAT]
+target prot opt source destination
+KUBE-MARK-MASQ all -- 10.32.2.9 0.0.0.0/0 /* default/nginx */
+DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 /* default/nginx */ tcp to:10.32.2.9:80
Chain KUBE-SERVICES (2 references)
target prot opt source destination
-KUBE-SVC-NPX46M4PTMTKRN6Y tcp -- 0.0.0.0/0 10.36.0.1 /* default/kubernetes:https cluster IP */ tcp dpt:443
-KUBE-SVC-VUMZCXJHDF5H4EWS tcp -- 0.0.0.0/0 10.36.3.159 /* kube-system/calico-typha:calico-typha cluster IP */ tcp dpt:5473
-KUBE-SVC-XP4WJ6VSLGWALMW5 tcp -- 0.0.0.0/0 10.36.8.228 /* kube-system/default-http-backend:http cluster IP */ tcp dpt:80
-KUBE-SVC-QMWWTXBG7KFJQKLO tcp -- 0.0.0.0/0 10.36.3.123 /* kube-system/metrics-server cluster IP */ tcp dpt:443
-KUBE-SVC-XBBXYMVKK37OV7LG tcp -- 0.0.0.0/0 10.36.4.218 /* gmp-system/gmp-operator:webhook cluster IP */ tcp dpt:443
KUBE-SVC-TCOU7JCQXEZGVUNU udp -- 0.0.0.0/0 10.36.0.10 /* kube-system/kube-dns:dns cluster IP */ udp dpt:53
KUBE-SVC-ERIFXISQEP7F7OF4 tcp -- 0.0.0.0/0 10.36.0.10 /* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:53
+KUBE-SVC-2CMXP7HKUVJN7L6M tcp -- 0.0.0.0/0 10.36.10.234 /* default/nginx cluster IP */ tcp dpt:80
+KUBE-EXT-2CMXP7HKUVJN7L6M tcp -- 0.0.0.0/0 35.221.94.105 /* default/nginx loadbalancer IP */ tcp dpt:80
+KUBE-SVC-XBBXYMVKK37OV7LG tcp -- 0.0.0.0/0 10.36.4.218 /* gmp-system/gmp-operator:webhook cluster IP */ tcp dpt:443
+KUBE-SVC-XP4WJ6VSLGWALMW5 tcp -- 0.0.0.0/0 10.36.8.228 /* kube-system/default-http-backend:http cluster IP */ tcp dpt:80
+KUBE-SVC-QMWWTXBG7KFJQKLO tcp -- 0.0.0.0/0 10.36.3.123 /* kube-system/metrics-server cluster IP */ tcp dpt:443
+KUBE-SVC-NPX46M4PTMTKRN6Y tcp -- 0.0.0.0/0 10.36.0.1 /* default/kubernetes:https cluster IP */ tcp dpt:443
+KUBE-SVC-VUMZCXJHDF5H4EWS tcp -- 0.0.0.0/0 10.36.3.159 /* kube-system/calico-typha:calico-typha cluster IP */ tcp dpt:5473
KUBE-NODEPORTS all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
+Chain KUBE-SVC-2CMXP7HKUVJN7L6M (2 references) [負荷分散]
+target prot opt source destination
+KUBE-MARK-MASQ tcp -- !10.32.1.0/24 10.36.10.234 /* default/nginx cluster IP */ tcp dpt:80
+KUBE-SEP-DZECBLFBK3Q7X4I5 all -- 0.0.0.0/0 0.0.0.0/0 /* default/nginx -> 10.32.1.12:80 */ statistic mode random probability 0.33333333349
+KUBE-SEP-FLZ7GUCVWEOYSVXC all -- 0.0.0.0/0 0.0.0.0/0 /* default/nginx -> 10.32.2.9:80 */ statistic mode random probability 0.50000000000
+KUBE-SEP-44W4V6DCT4JUKJOF all -- 0.0.0.0/0 0.0.0.0/0 /* default/nginx -> 10.32.3.14:80 */iptablesのチェインを順に追っていくと下のようになります。ベースチェインはPREROUTINGとなり、KUBE~というレギュラーチェインにジャンプして、ルールマッチを行います。 PREROUTINGでフックされ、確率に基づいてどのポッドにルーティングするか決め、DNATにより宛先IPアドレスをCluster IPからPod IPへ変更することで、Podにパケットが到達します。
PREROUTING
|- KUBE-SERVICES
|- KUBE-SVC-2CMXP7HKUVJN7L6M[負荷分散]
|- KUBE-SEP-44W4V6DCT4JUKJOF[DNAT]
|- KUBE-SEP-DZECBLFBK3Q7X4I5[DNAT]
|- KUBE-SEP-FLZ7GUCVWEOYSVXC[DNAT](補足) ワーカーノードを特定して、sshでアクセスし、iptablesコマンドを実行しなくても、kube-proxyのPodからiptablesコマンドを実行しても同じ結果が確認できます。
// kubectlを使って、iptablesを確認する
$ kubectl exec -it kube-proxy-gke-gke-dataplane-v1-default-pool-c61696b8-1qkj -n kube-system -- iptables -t nat -n -LGKE Dataplane V2
次に、GKE Dataplane V2を使用するクラスターを作成します。
–enable-dataplane-v2 で GKE Dataplane V2を使用できます。また、--image-type ubuntu_containerd により、ワーカーノードのOSをUbuntuに指定して作成しました。GKEでは、デフォルトの設定だとワーカーノードに Container-Optimized OSを使います。しかし、このOSにはaptなどといったパッケージ管理ツールが入っておらず、この後使うbpftoolをインストールするのに苦労したため、Ubuntuに変更しました。
※ Container-Optimized OSでもtoolboxを使用して、パッケージやツールをインストールできるようです。 https://cloud.google.com/container-optimized-os/docs/how-to/toolbox?hl=ja
# "gke-dataplane-v2-ubuntu"クラスターを作成します
$ gcloud container clusters create gke-dataplane-v2-ubuntu --zone asia-northeast1-a --enable-dataplane-v2 --image-type ubuntu_containerdクラスターが作成できたら、GKE Dataplane V1と同じ構成でDeploymentとServiceを作成し、外部からアクセスできることを確認します。
# nginxのPodを3つ作るDeploymentを作成
$ kubectl create deployment nginx-deployment --image=nginx --replicas=3
# 外部に公開するためのServiceを作成
$ kubectl expose deployment nginx-deployment --type=LoadBalancer --name=nginx --port=80 --target-port=80
# 3ノードでnginxポッドが3つ動いており、service/nginxにEXTERNAL-IPが付与されていることを確認
$ kubectl get pods,deployment,svc -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/nginx-deployment-c97d784bc-8kz7v 1/1 Running 0 27h 10.12.2.16 gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-1w8l <none> <none>
pod/nginx-deployment-c97d784bc-ctgvx 1/1 Running 0 27h 10.12.1.7 gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-j93z <none> <none>
pod/nginx-deployment-c97d784bc-fczpd 1/1 Running 0 27h 10.12.0.8 gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-v5dz <none> <none>
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment.apps/nginx-deployment 3/3 3 3 27h nginx nginx:1.25.4 app=nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.106.80.1 <none> 443/TCP 3d3h <none>
service/nginx LoadBalancer 10.106.82.189 35.190.239.53 80:31607/TCP 70s app=nginx
# EXTERNAL-IPにアクセスする
$ curl 35.190.239.53
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
~ 省略 ~次に、kube-system NamespaceのPodを見てみると、kube-proxyのPodがなく、また、anetdというPodが新たに作成されていることが確認できます。GKEでは、このanetdによって eBPFプログラムを操作します。
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
anetd-dhhct 1/1 Running 0 3d3h
anetd-vj2p9 1/1 Running 0 3d3h
anetd-xf2t8 1/1 Running 0 3d3h
antrea-controller-horizontal-autoscaler-67df5fcf9-p255v 1/1 Running 0 3d3h
event-exporter-gke-5b8bcb44f7-7z5q5 2/2 Running 0 3d3h
fluentbit-gke-87tjz 2/2 Running 0 3d3h
fluentbit-gke-glcwd 2/2 Running 0 3d3h
fluentbit-gke-zvsbc 2/2 Running 0 3d3h
gke-metrics-agent-5r5rk 2/2 Running 0 3d3h
gke-metrics-agent-crvkb 2/2 Running 0 3d3h
gke-metrics-agent-mtplj 2/2 Running 0 3d3h
konnectivity-agent-7d8495b885-pwnwn 1/1 Running 0 3d3h
konnectivity-agent-7d8495b885-stdft 1/1 Running 0 3d3h
konnectivity-agent-7d8495b885-tsrq7 1/1 Running 0 3d3h
konnectivity-agent-autoscaler-5d9dbcc6d8-qzflf 1/1 Running 0 3d3h
kube-dns-6f9b8847ff-nh77t 4/4 Running 0 3d3h
kube-dns-6f9b8847ff-zcpth 4/4 Running 0 3d3h
kube-dns-autoscaler-84b8db4dc7-gqbmq 1/1 Running 0 3d3h
l7-default-backend-cf7cdc6f6-6rkwc 1/1 Running 0 3d3h
metrics-server-v0.5.2-8fb865474-mqdrw 2/2 Running 0 3d3h
netd-g2zbh 1/1 Running 0 3d3h
netd-l222r 1/1 Running 0 3d3h
netd-zzmml 1/1 Running 0 3d3h
pdcsi-node-fn4vt 2/2 Running 0 3d3h
pdcsi-node-ngkqw 2/2 Running 0 3d3h
pdcsi-node-rpjd8 2/2 Running 0 3d3hkube-proxyのPodがないことは確認しましたが、念のため、GKE Dataplane V1と同じように各ワーカーノードのiptablesのルールを見てみます。
// ワーカーノードを確認
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-1w8l Ready <none> 3d3h v1.27.8-gke.1067004
gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-j93z Ready <none> 3d3h v1.27.8-gke.1067004
gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-v5dz Ready <none> 3d3h v1.27.8-gke.1067004
// gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-1w8l にsshでアクセスする
$ gcloud compute ssh --project "sreake-intern" --zone "asia-northeast1-a" "gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-1w8l"
// iptablesのルールを表示する(-t nat:NATテーブルを指定, -L:リスト形式, -n:IPアドレスとポート番号を数値で出力 )
kobayashi@gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-1w8l:~$ sudo iptables -t nat -L -n
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
CILIUM_PRE_nat all -- 0.0.0.0/0 0.0.0.0/0 /* cilium-feeder: CILIUM_PRE_nat */
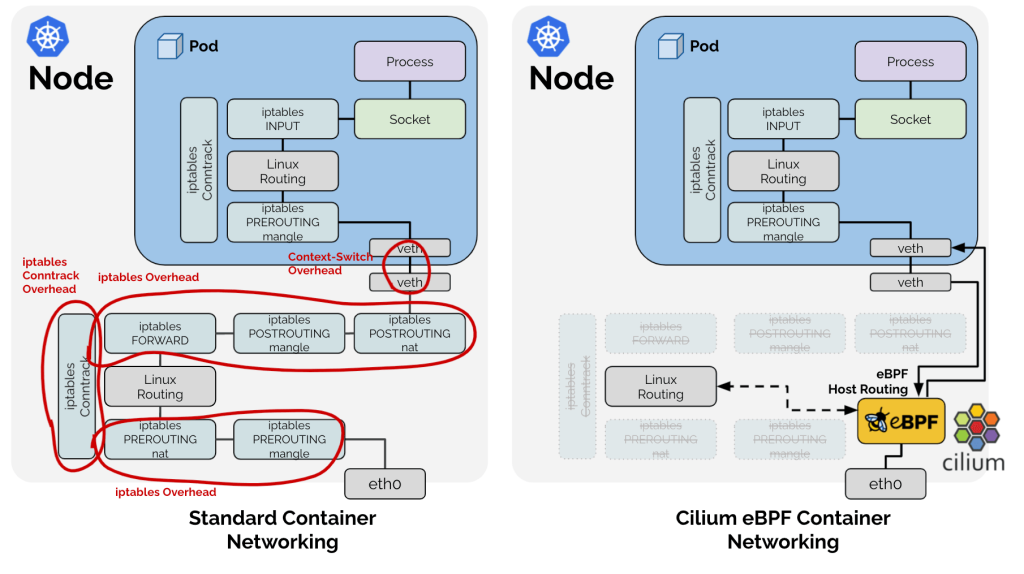
~ 省略 ~iptablesのNATテーブルにルールはいくつかありますが、GKE Dataplane V1にあったような負荷分散やDNATを行うルールは書かれていません。つまり、iptablesを使わずに、負荷分散やDNATを行なっています。
ではどうやって、負荷分散やDNATを行なっているのかというとeBPFで実現しています。
実際にどのようなeBPFプログラムがロードされているのかを見ていきます。そのために、bpftool を使用します。
bpftoolのREADME.mdに従って、インストールしていきます。
$ sudo apt update
$ sudo apt install -y build-essential libbpf-dev libbfd-dev libcap-dev clang llvm linux-tools-generic
$ git clone --recurse-submodules https://github.com/libbpf/bpftool.git
$ cd bpftool/src
$ make
$ sudo make install
$ bpftool -vbpftoolで確認したところ、たくさんのeBPFプログラムが動いていることがわかりました。
# カーネルのネットワークサブシステムにアタッチされたeBPFプログラムを出力
kobayashi@gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-1w8l:~$ bpftool net show
xdp:
tc:
ens4(2) clsact/ingress bpf_netdev_ens4.o:[from-netdev] id 1198
ens4(2) clsact/egress bpf_netdev_ens4.o:[to-netdev] id 1212
cilium_net(4) clsact/ingress bpf_host_cilium_net.o:[to-host] id 1187
cilium_host(5) clsact/ingress bpf_host.o:[to-host] id 1165
cilium_host(5) clsact/egress bpf_host.o:[from-host] id 1176
gke10cc00139cf(6) clsact/ingress bpf_lxc.o:[from-container] id 1232
gke10cc00139cf(6) clsact/egress bpf_lxc.o:[to-container] id 1268
gkebaa31a25f0d(7) clsact/ingress bpf_lxc.o:[from-container] id 1360
gkebaa31a25f0d(7) clsact/egress bpf_lxc.o:[to-container] id 1396
gkef12843434d3(8) clsact/ingress bpf_lxc.o:[from-container] id 1300
gkef12843434d3(8) clsact/egress bpf_lxc.o:[to-container] id 1332
gke13e603439a4(9) clsact/ingress bpf_lxc.o:[from-container] id 1296
gke13e603439a4(9) clsact/egress bpf_lxc.o:[to-container] id 1330
gkeea31b5930af(10) clsact/ingress bpf_lxc.o:[from-container] id 1234
gkeea31b5930af(10) clsact/egress bpf_lxc.o:[to-container] id 1264
gkeea6d60bc5bd(11) clsact/ingress bpf_lxc.o:[from-container] id 1426
gkeea6d60bc5bd(11) clsact/egress bpf_lxc.o:[to-container] id 1458
gke69f36b724a6(12) clsact/ingress bpf_lxc.o:[from-container] id 1365
gke69f36b724a6(12) clsact/egress bpf_lxc.o:[to-container] id 1394
gke65194a809f1(13) clsact/ingress bpf_lxc.o:[from-container] id 1475
gke65194a809f1(13) clsact/egress bpf_lxc.o:[to-container] id 1496
gkeb2d74f759f1(16) clsact/ingress bpf_lxc.o:[from-container] id 1603
gkeb2d74f759f1(16) clsact/egress bpf_lxc.o:[to-container] id 1620
gke70d082814fd(18) clsact/ingress bpf_lxc.o:[from-container] id 1675
gke70d082814fd(18) clsact/egress bpf_lxc.o:[to-container] id 1692
flow_dissector:
netfilter:
そこで、DeploymentやServiceを作る前後でロードされたeBPFプログラムがどのように変わるのかを確かめました。すると、DeploymentによりワーカーノードにPodが作成されたタイミングでeBPFプログラムが追加されました。下に、Podを作成する前後のロードされたeBPFプログラムの差分(加工済み)を示しています。
IDが2651と2668のeBPFプログラムが新たに作成されて、tcにアタッチされたことがわかります。
xdp:
tc:
ens4(2) clsact/ingress bpf_netdev_ens4.o:[from-netdev] id 1198
~ 省略 ~
gke70d082814fd(18) clsact/egress bpf_lxc.o:[to-container] id 1692
+gke2dcef5c7a49(21) clsact/ingress bpf_lxc.o:[from-container] id 2651
+gke2dcef5c7a49(21) clsact/egress bpf_lxc.o:[to-container] id 2668
flow_dissector:
netfilter:上記のように、Ciliumでは、負荷分散やDNATをxdpではなく、tcで実現しています。
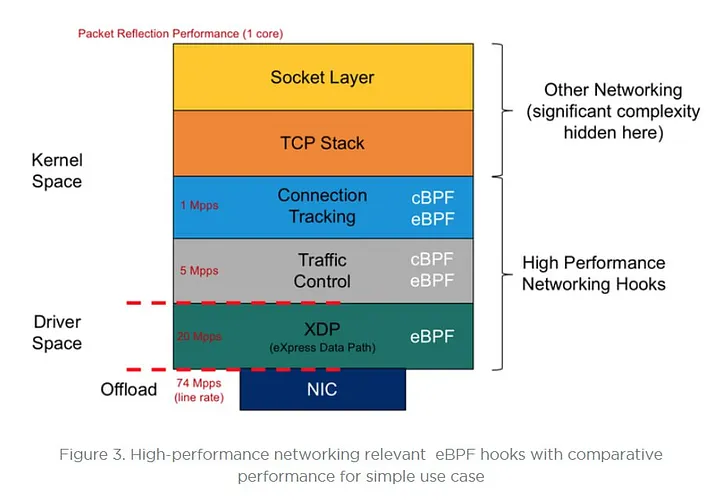
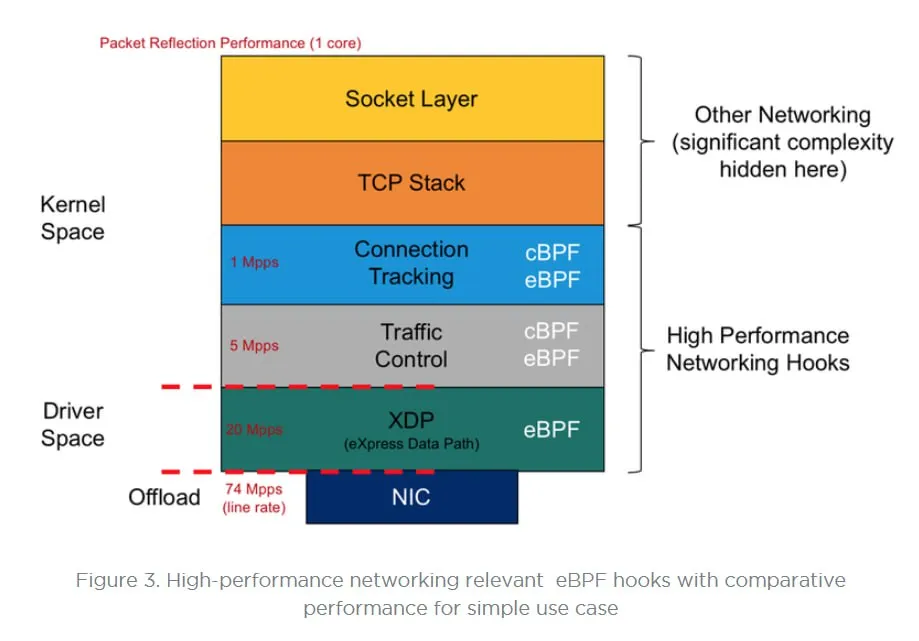
XDPとTCはどちらもeBPFプログラムを実行できるフレームワークですが、以下のような違いがあります。一部重複する用途もありますが、それぞれ異なる用途に適しており、組み合わせて使われています。
XDPとは、eXpress Data Pathの略で、ネットワークドライバがパケットを受信した時点でeBPF プログラムを実行します。バッファ割り当てやパケット解析の前にeBPFプログラムを実行するため、sk_buff を参照できません。そのため、非常に高速にパケットを処理することができますが、sk_buffのメタデータの読み取り・書き込みができません。また、ingressのみ処理を行うことができます。DDoS緩和や負荷分散といった用途で使用されています。
XDPの詳細については、以下のドキュメントをご覧ください。
https://docs.cilium.io/en/stable/bpf/progtypes/#xdp
一方で、TC とは、Traffic Controlの略で、パケットを解析してパケットのデータをsk_buffに保存した後に eBPFプログラムを実行します。そのため、XDPよりもコストはかかりますが、sk_buffを参照でき、メタデータの読み取り・書き込みも可能です。また、ingress/egress両方で処理を行うことができます。コンテナのネットワークポリシー適用や負荷分散、モニタリングといった用途で使用されています。
Ciliumの詳細については、以下のドキュメントをご覧ください。
https://docs.cilium.io/en/stable/bpf/progtypes/#tc-traffic-control
{kind=link}
さらなる調査として、IDが2651のeBPFプログラムの詳細とこのeBPFプログラムが参照しているBPF MAPを見てみました。
新たに追加されたeBPFプログラムは、handle_xgressというプログラムであり、2つのBPF Mapを参照していることがわかりました。そこで、参照しているBPF Mapを出力すると、Key-Valueペアのバイト列が表示されましたが、これだけでは、このバイト列が何なのかわかりません。そのため、次の章では、実装を追いながら調査していきます。
# eBPFプログラムの詳細をJSON形式で出力
kobayashi@gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-1w8l:~$ sudo bpftool prog show id 2651 --pretty
{
"id": 2651, # プログラムID
"type": "sched_cls", # プログラムタイプ
"name": "handle_xgress", # プログラム名
"tag": "7e57114af5fa2491", # プログラムの命令から生成したSHAの計算結果
"gpl_compatible": true, # GPLとライセンスの互換性がある
"loaded_at": 1711695500, # プログラムがロードされたタイムスタンプ
"uid": 0, # ROOTがプログラムをロード
"orphaned": false,
"bytes_xlated": 656, # 656バイトのeBPFバイトコード
"jited": true, # JITコンパイルでeBPFバイトコードから機械語に変換
"bytes_jited": 476, # 476バイトの機械語に翻訳
"bytes_memlock": 4096, # 4096バイトのページアウトされないメモリを確保
"map_ids": [286,113 # IDが286と113のBPF Mapを参照
],
"btf_id": 543
}
# IDが286のBPF Mapを出力
kobayashi@gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-1w8l:~$ sudo bpftool map dump id 286
key: 01 00 00 00 value: 63 0a 00 00
~ 省略 ~
key: 26 00 00 00 value: 65 0a 00 00
Found 8 elements
# IDが113のBPF Mapを出力
kobayashi@gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-1w8l:~$ sudo bpftool map dump id 113
key:
9e 02 00 00 00 00 00 00
value (CPU 00): 04 00 00 00 00 00 00 00 9c 01 00 00 00 00 00 00
value (CPU 01): 08 00 00 00 00 00 00 00 68 03 00 00 00 00 00 00
~ 省略 ~
key:
85 02 00 00 00 00 00 00
value (CPU 00): 08 00 00 00 00 00 00 00 50 02 00 00 00 00 00 00
value (CPU 01): 04 00 00 00 00 00 00 00 28 01 00 00 00 00 00 00
Found 5 elementskube-proxyとCiliumの実装を追う
kube-proxy
今回使用したGKEのバージョンである 1.27.8-gke.1067004 では、Kubernetes v1.27を使用するため、kubernetes/kubernetes release-1.27 のソースコードを読んでいきます。
コードリーディングの際には以下のサイトを参考にしました。
iptablesの初期化
kube-proxy の処理は、cmd/kube-proxy/proxy.go のmain から始まります。これは、クラスター作成時に行われます。 cmd/kube-proxy/app/server.go のNewProxyCommandでコマンドオブジェクトを作成したら、 Run が呼び出されます。 その後、cmd/kube-proxy/app/server_others.go のnewProxyServer で IPv4 か IPv6 かを識別したのちに、pkg/proxy/iptables/proxier.go のNewProxierを呼び出して、iptables を初期化しています。
iptablesルールの作成・削除
pkg/proxy/iptables/proxier.go の NewProxier では、async.NewBoundedFrequencyRunnerに引数としてsyncProxyRules を渡すことで、 定期的にsyncProxyRulesを呼び出しています。このsyncProxyRulesでKubernetes EndpointSliceオブジェクトやServiceオブジェクトとiptablesを同期、つまり、iptablesルールの追加・削除を行っています。
では、GKE Dataplane V1 の検証で追加された iptablesルールはどこで作成されたのかを確認します。以下のようにして、iptablesルールを追加するために、どのようなコマンドを実行したのかを出力することができます。
kobayashi@gke-gke-dataplane-v1-default-pool-c61696b8-8esn ~ $ sudo iptables -t nat -S | grep KUBE-SEP-44W4V6DCT4JUKJOF
-N KUBE-SEP-44W4V6DCT4JUKJOF
-A KUBE-SEP-44W4V6DCT4JUKJOF -s 10.32.3.14/32 -m comment --comment "default/nginx" -j KUBE-MARK-MASQ
-A KUBE-SEP-44W4V6DCT4JUKJOF -p tcp -m comment --comment "default/nginx" -m tcp -j DNAT --to-destination 10.32.3.14:80
-A KUBE-SVC-2CMXP7HKUVJN7L6M -m comment --comment "default/nginx -> 10.32.3.14:80" -j KUBE-SEP-44W4V6DCT4JUKJOFこれらのコマンドは下に示すように、 syncProxyRules のL1394-L1422で文字列として、作られています。
// Generate the per-endpoint chains.
for _, ep := range allLocallyReachableEndpoints {
epInfo, ok := ep.(*endpointsInfo)
if !ok {
klog.ErrorS(nil, "Failed to cast endpointsInfo", "endpointsInfo", ep)
continue
}
endpointChain := epInfo.ChainName
// Create the endpoint chain
proxier.natChains.Write(utiliptables.MakeChainLine(endpointChain))
activeNATChains[endpointChain] = true
args = append(args[:0], "-A", string(endpointChain))
args = proxier.appendServiceCommentLocked(args, svcPortNameString)
// Handle traffic that loops back to the originator with SNAT.
proxier.natRules.Write(
args,
"-s", epInfo.IP(),
"-j", string(kubeMarkMasqChain))
// Update client-affinity lists.
if svcInfo.SessionAffinityType() == v1.ServiceAffinityClientIP {
args = append(args, "-m", "recent", "--name", string(endpointChain), "--set")
}
// DNAT to final destination.
args = append(args, "-m", protocol, "-p", protocol, "-j", "DNAT", "--to-destination", epInfo.Endpoint)
proxier.natRules.Write(args)
}Cilium
次に、Ciliumでkube-proxyの置き換えがどのように実装されているかを見ていきます。
今回使用したクラスターではバージョン1.12.10 の Ciliumを使用していることから、cilium/cilium v1.12.10 のソースコードを読んでいきます。
バージョンの確認方法についてはこちらの記事を参考にしました。
https://www.doit.com/ebpf-cilium-dataplane-v2-and-all-that-buzz-part-2/
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
anetd-dhhct 1/1 Running 0 4d4h
anetd-vj2p9 1/1 Running 0 4d4h
anetd-xf2t8 1/1 Running 0 4d4h
antrea-controller-horizontal-autoscaler-67df5fcf9-p255v 1/1 Running 0 4d4h
event-exporter-gke-5b8bcb44f7-7z5q5 2/2 Running 0 4d4h
fluentbit-gke-87tjz 2/2 Running 0 4d4h
fluentbit-gke-glcwd 2/2 Running 0 4d4h
fluentbit-gke-zvsbc 2/2 Running 0 4d4h
gke-metrics-agent-5r5rk 2/2 Running 0 4d4h
gke-metrics-agent-crvkb 2/2 Running 0 4d4h
gke-metrics-agent-mtplj 2/2 Running 0 4d4h
konnectivity-agent-7d8495b885-pwnwn 1/1 Running 0 4d4h
konnectivity-agent-7d8495b885-stdft 1/1 Running 0 4d4h
konnectivity-agent-7d8495b885-tsrq7 1/1 Running 0 4d4h
konnectivity-agent-autoscaler-5d9dbcc6d8-qzflf 1/1 Running 0 4d4h
kube-dns-6f9b8847ff-nh77t 4/4 Running 0 4d4h
kube-dns-6f9b8847ff-zcpth 4/4 Running 0 4d4h
kube-dns-autoscaler-84b8db4dc7-gqbmq 1/1 Running 0 4d4h
l7-default-backend-cf7cdc6f6-6rkwc 1/1 Running 0 4d4h
metrics-server-v0.5.2-8fb865474-mqdrw 2/2 Running 0 4d4h
netd-g2zbh 1/1 Running 0 4d4h
netd-l222r 1/1 Running 0 4d4h
netd-zzmml 1/1 Running 0 4d4h
pdcsi-node-fn4vt 2/2 Running 0 4d4h
pdcsi-node-ngkqw 2/2 Running 0 4d4h
pdcsi-node-rpjd8 2/2 Running 0 4d4h
$ kubectl exec -it anetd-dhhct -n kube-system -- bash
Defaulted container "cilium-agent" out of: cilium-agent, clean-cilium-state (init), apply-sysctl-overwrites (init), install-cni-binaries (init)
root@gke-gke-dataplane-v2-ubu-default-pool-fa4ad905-1w8l:/home/cilium# cilium version
Client: 1.12.10 0e5a4a2740 2023-10-05T06:05:06+00:00 go version go1.20.10 linux/amd64
Daemon: 1.12.10 0e5a4a2740 2023-10-05T06:05:06+00:00 go version go1.20.10 linux/amd64コードリーディングの際には以下のサイトを参考にしました。
https://arthurchiao.art/blog/cilium-life-of-a-packet-pod-to-service
また、Cilium で使用される eBPF プログラムは cilium/bpf ディレクトリに格納されています。 https://docs.cilium.io/en/stable/contributing/development/codeoverview/
前章では、GKE Dataplane V2を使用した場合、iptablesではなくeBPFでDNATを行っていることがわかりました。そこで、DNAT の処理を実行している eBPF プログラムを探しました。
DNATは cilium/bpf/bpf_lxc.c の handle_ipv4_from_lxc 関数内で行われています。handle_xgress → tail_handle_ipv4_cont→handle_ipv4_from_lxc の順に呼び出されています。
まず、パケットのヘッダ情報が handle_xgress に送信され、L3 プロトコルがチェックされます。
次にIPv4パケットが tail_handle_ipv4_cont に渡されます。さらに、handle_ipv4_from_lxc がTail Callとして呼び出されます。この関数の中で、宛先アドレスがServiceIPから宛先PodのIPアドレスに書き換えられます。
感想
小林
以前から、Kubernetes や eBPF という用語は知っていましたが、何から始めていいか分からない状態でした。そんななか、今回のインターンを通して、自分だけではなかなか始めることのできない GKEでのクラスター作成や kube-proxy の実装を追うといったことをメンターの方々の助けを得ながらも取り組めたのはよかったです。また、実装を見ていく中で、ブラックボックスだった部分がわかることの楽しさを再認識できたのもよかったと思います。これからも、ネットワークやコンテナ技術などさらなる勉学に励んでいきたいです。
中村
インターンを始める前は Kubernetes や Cilium についての知識や経験がほとんどなかったのですが、技術調査を通してこれらの技術がどのようにして実現されているか・使われているかを知り、解像度が上がりました。また、Cilium のようなコードベースの大きな OSS のコードを読む経験をすることができたのも良かったと思います。そして、本インターンを通してより eBPF への興味が湧いたので、インターン後も個人開発などを通して深掘りしていきたいです。