
こんにちは、初めましての方もそうでない方も、Sreake事業部 佐藤慧太(@SatohJohn)です。
今回Google CloudのVertex AI Search(旧Enterprise Search)について検証のため、Notionのデータを集約して、社内Knowledgeの検索を行うアプリケーションを作成しましたので、こちらについて報告させてもらいます。
Vertex AI Search and Conversationとは
Enterprise Search | Google Cloud
社内ドキュメントやpdfなどの情報をGCSまたはBigQueryに配置し、DataSourceとして作成し、検索を行うことができる機能になっています。
この検索(Search)の際に、検索結果の要約をして提示し、その根拠の文章を提示してくれます。また、会話形式(Conversation)での深掘りもできます。
まとめると以下のような機能を持ちます。
- Google 検索のSearchLabにおけるSearch Generative Experience(SGE)のような文章検索ができるサービスである
- 対象となるのがPDF, HTML, TXTです。DOC and PPTX は Previewですが使用可能
- Enterpriseなので他の場所にデータが出ることはない
- 検索の履歴でどのような結果が返っているか、ユーザがどのような検索をしているのかを分析することが可能
今回はこのVertex AI Searchを使って社内KnowledgeであるNotionを取り込み、検索できるようにしました。よくあるNotionの検索性が悪いという課題を解消できればと考えています。
アーキテクチャ
全体の構成は以下のようになっています。
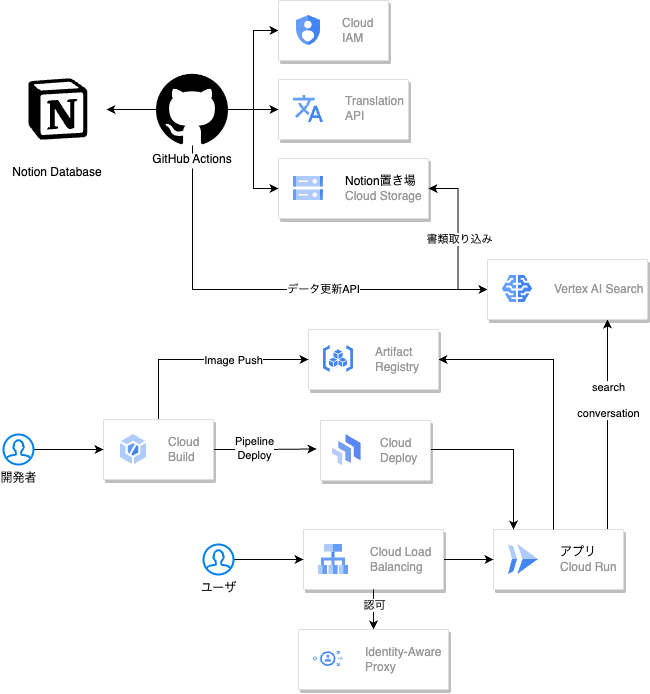
基本的には、2つに分かれています。残りは開発者の部分なので気にしなくても良いです。
1.データを貯める部分
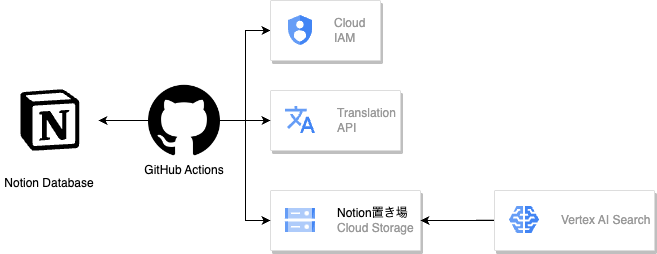
まず、Notionの対象のDatabaseからGitHub Actions + Workload Identity Federationを使って、GCSに配置しています。後述しますが、日本語でドキュメントを作成しているため Translation APIを使って、英語に翻訳をしております。
GitHub Actionsを利用しているのは、すでに社内Knowledgeの更新を周知するSlackBotが、こちらをもとに動いていたためです。
上記を1日に一度実行して、Vertex AI SearchによるGCSのデータ取り込みを行い、データの更新が完了します。
? データ更新には以下のAPIを利用しております
https://cloud.google.com/generative-ai-app-builder/docs/reference/rest/v1beta/projects.locations.dataStores.branches.documents/import
注意事項としては、GCSのデータは、10万件を超えないようにしなければいけません。
Required. Cloud Storage URIs to input files. URI can be up to 2000 characters long. URIs can match the full object path (for example,gs://bucket/directory/object.json) or a pattern matching one or more files, such asgs://bucket/directory/*.json.
A request can contain at most 100 files (or 100,000 files if dataSchema is content). Each file can be up to 2 GB (or 100 MB if dataSchema is content).
そのため、大量のデータを扱われる場合、GCSへのデータの置き方というのも重要な設計の要因になります。
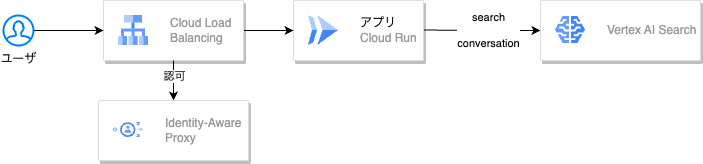
2.データを取得する部分
IAPを挟むことで社内限定にしつつ、IDを取得することができるため、後述するconversationがユーザごとに作成できます。会話履歴などのデータは基本的にVertex AI Searchがもってくれているため、DBなどはありません。
画面イメージ
現在UIは仮で作成しています。
メニュー
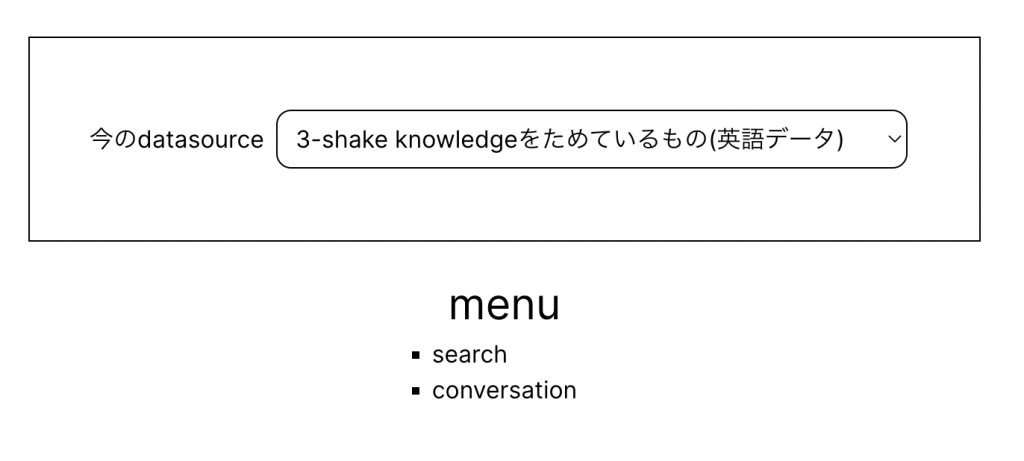
- こちらでデータソースを切り替えをして、どのデータソースに対して問い合あわせをするかを決めます。
- データソースに対するインタフェースは共通しているため、このような形で一度作成しています。
search
画面
- 入力文字に対してのvertex AIによる回答が返ってきます
- ドキュメントの検索になるため、根拠となるドキュメントが取得できるため、リンクをクリックして取得できる様になっています
実装
- 今回Next.jsのAppRouterを使ってAPIとUIを作成しています。そのため、Node.jsのclientを使うことを考えたのですが、検索のSummaryが取得できず、やむを得ずAPIを叩くようにしました。
- リクエスト時に
contentSearchSpec.summarySpecsummaryResultCountを含めることで結果にsummaryが含まれるようになります - APIのresponseは以下のようになっております。
{
"results": [
{
"id": "{documentId}",
"document": {
"name": "projects/{projectId}/locations/global/collections/default_collection/dataStores/{document}",
"id": "{documentId}",
"derivedStructData": {
"link": "gs://{bucketName}/DocPath.txt",
"extractive_answers": [
{
"content": "..."
}
]
}
}
}...
],
"totalSize": 385,
"attributionToken": "{token}",
"nextPageToken": "{paging_token}",
"guidedSearchResult": {},
"summary": {
"summaryText": "{summary}",
"safetyAttributes": {
"categories": [
"Finance"
],
"scores": [
0.2
]
}
}
}? linkの部分はDatasourceが、Webの場合はそのままページのURLが入ってきます。
また、ここの safetyAttributes というのがよくわからないので現状は使っていないのですが、おそらく、確証度のようなものだと推測しています。
conversation
画面
- 会話の作成をして、それについて深掘りができるようになっています
- ユーザごとに会話の履歴が取得できるようになっており、ChatGPTのような使い方になっております
実装
- 会話の履歴データをVertex AI Searchの方で保持しているため、これを利用しています
- 会話の作成時に
userPseudoIdとして、uidを渡すことができるため、取得時には、userPseudoIdでfilterすることで、ユーザのものだけを取得するようにしています- uidはIAPを使っているため、Request Headerについて来るのを利用しています
- searchのように、documentsが取得できないようでしたので、ここは一旦諦めております
検証した感想
Vertex AI Search And Conversationの良い部分
- 社内のドキュメントをpdfでもdocx、pptxでも良いので保存しておくことで、扱える点
- 今後マークダウンなどの対応できる記法が増えてくるとより嬉しいと思います
- site検索でもdocument検索でもUIが変わらない点
- BigQueryでも基本interfaceは変わらないと思いますがdocumentsの部分がどうなるのかは現在検証中です
- 現状は日本語データを扱っても、特に違和感が無い結果が返ってくることが多い
- はじめは英語データでないとうまく検索できないこともありましたが、検証途中から精度が高くなった印象です
- 言語modelの変更などをSaaS側に任せておける
- 検索に使うデータの加工や、集積方法を検討することに集中できるのが良いと思いました
Vertex AI Search And Conversationの今後に期待な部分
- データ数が少ないと、適当な回答になり良い結果が返ってこない (ハルシネーションが起きる)
- 一般的なデータに関しては、おそらく既存のもので代用しているようなので、ここはどうデータを貯めるかが大事かと思いました
- ApplicationとDataSourceは1:1で変更ができない
- ApplicationとDataSource=1:* または、付替えができるなど、できればより使いやすさが変わるかなとも思いました
- DataSourceにはWebページというものが有るが、認証が必要なprivateなページは参照が出来ない
- そのため、現状では、publicにネットに出回っている情報でのものになるため、Google 検索におけるデータとあまり差が無いと感じます
- excludeができるため、ある程度出さないデータというのを作成できるのは一つ差かもしれないです
- ただ、Vertex AI Data ConnectorsによりJIRAやsalesforceなどの検索ができるようになったと、あるので、このようにDataSourceが増えていくことになるのかと感じております
- https://cloud.google.com/generative-ai-app-builder/docs/create-data-store-es
- そのため、現状では、publicにネットに出回っている情報でのものになるため、Google 検索におけるデータとあまり差が無いと感じます
まとめ
今回VertexAI Search and Conversationを使ってNotion内のknowledge検索を行ってみました。
自身で使っている限りはまだまだ、データが足りないためか精度などは良くないと思います。
古いデータをGCSにuploadしてみてどうなるかなども試していきたいと思います。
今後
- uidを使い、より複雑なことを検証していく予定です
- search、conversationsにおける閲覧権限制御を行う
- optionではありますが、ユーザイベントを取り込むことによる検索結果のランキングの向上が見込める可能性がある
- 他のデータではどうなるかを検証してみます
- Google Drive上のデータを一度すべてかっさらってきてPPTなどのドキュメントを入れてみてどうなるかを見る