
1. はじめに
はじめまして、Sreake事業部の井上 秀一です。私はSreake事業部にて、SREや生成AIに関するResearch & Developmentを行っています。
本記事では、Google Cloudが提供するプロンプト比較機能の使い方、機能に関する調査内容をまとめています。
2. 言語モデルにおけるプロンプトと設計
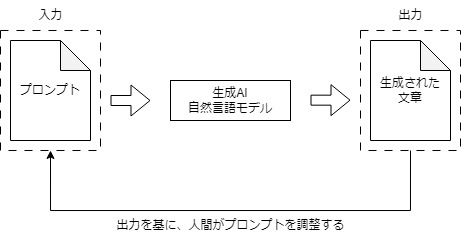
言語モデルにおけるプロンプトとは、言語モデルから望ましいレスポンスを引き出すための命令文(プロンプト)の事を指します。プロンプトとして、以下のような例が挙げられます。プロンプトの設計は、言語モデルからの正確で高品質なレスポンスを実現するための必要な工程です。例えば次の質問を言語モデルに入力すると考えます。
SREとPlatform Engineeringの違いについて教えてください。
上記質問に携えるプロンプト例として、以下が挙げられます。
- 人格の付与: 貴方はPlatform Engineeringチームのエンジニアです。
- 回答方法の提示: 箇条書きで回答して。
- 背景情報の提示: 私は新卒でこのチームにジョインしました。
同じような内容のプロンプトでも、書き方や組み合わせによっても、言語モデルからの解答が異なります。例として次のようなプロンプトが考えられます。
- 貴方はPlatform Engineeringチームのエンジニアです。
- 貴方はPlatform Engineeringチームのチーフエンジニアです。
- 貴方はPlatform Engineeringチームのエンジニアで、私はこのチームにジョインした新卒です。
言語モデルの入力(プロンプト)と出力を比較して、より良いプロンプトを設計していく過程がプロンプト設計です。また、プロンプト設計に関する一般的な戦略や、プロンプトサンプルに関するドキュメントがGoole Cloudにて提供されています。
以上のようなプロンプト設計の過程で、メッセージを何度もリクエストして、入力と出力を記録して、評価するという手法は煩雑で、それこそToilになります。次章では、プロンプト設計の煩雑さを大幅軽減するGoogle Cloudのプロンプト比較機能の利用を提案します。
3. Google Cloudのプロンプト比較機能とは?
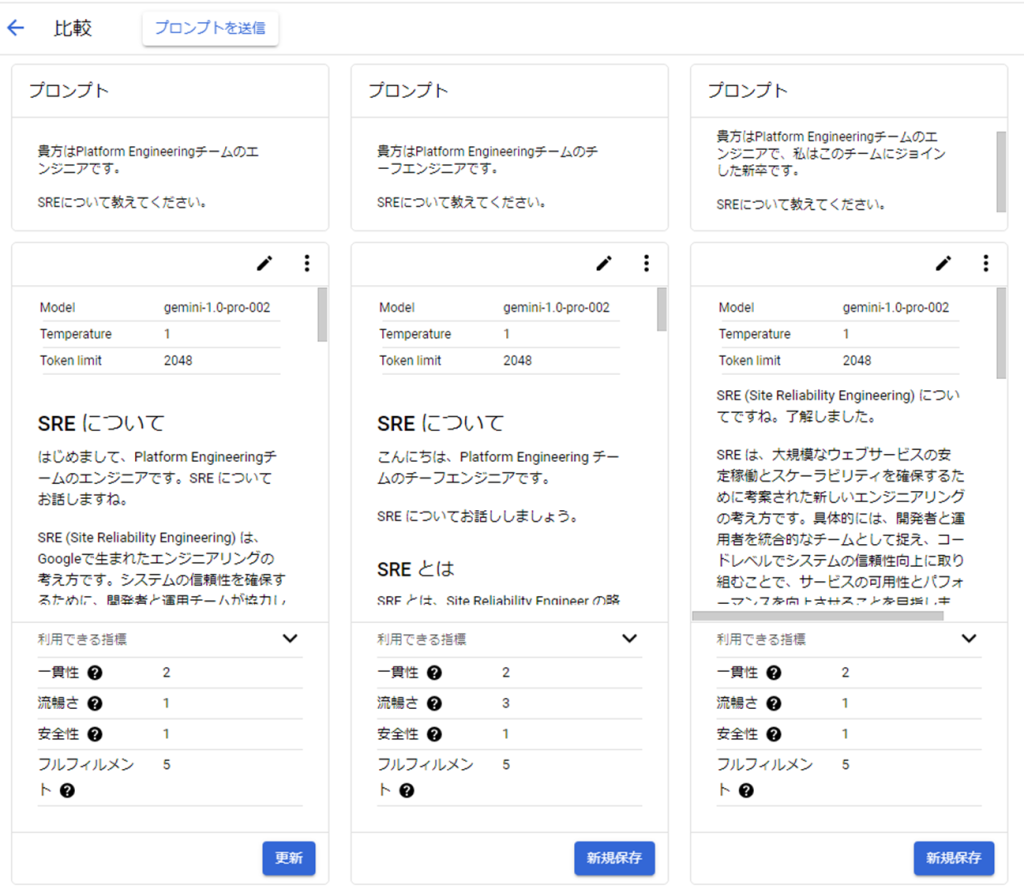
上記図は、プロンプト比較機能です。Vertex AI Studioでは、モデルごとのプロンプト出力を比較する機能が追加されています。入力(プロンプト)を微調整しつつ、並行して試行できるため、プロンプト設計時の煩雑さが解消されます。
プロンプト比較機能できること、機能について
- 比較
- 最大3つの並列比較
- モデル
- パラメーター調整:
Temperature、出力トークンの上限etc… - 安全性設定:
悪意のある表現、危険なコンテンツ、性的に露骨な表現、ハラスメントに対する応答を制限する。各有害コンテンツに対して、少量、一部、ほとんど、を選べる。 - 根拠づけ:
Vertex AI Search、Google検索 - 利用できるLLMモデル:
Gemini、PaLM2シリーズのみ
- パラメーター調整:
- 評価機能
- 指標(スコア)の算出:
一貫性、流暢さ、安全性、フルフィルメント(詳細) - グラウンドトゥルース:
解答の文章を記述する事で、追加の指標(ROUGE、BLEU)を用いてモデル出力を評価できる。
- 指標(スコア)の算出:
指標(スコア)について
各出力に対して、指標が提供されています。各指標の算出にはLLMモデルが用いられています。以下は各指標の説明です。グラウンドトゥルースが有効の場合は追加の指標が得られます。
- 通常の指標
- 一貫性:
生成された出力が整然とした構造を持ち、一貫性があり、前後する文章の間に論理的な流れがあるかを評価したスコアです。
LLM モデルを使用し、その生成された出力を評価することにより、一貫性のスコアが求められます。一貫性のスコアは 1(最低)~5(最高)の範囲で評価されます。 - 流暢さ:
生成された出力の文法と言語的な正確性を評価したスコアです。LLM モデルを使用し、その生成された出力を評価することにより、流暢さのスコアが求められます。
流暢さのスコアは 1(最低)~5(最高)の範囲で評価されます - 安全性:
生成された出力が、ヘイトスピーチ、ハラスメント、性的に露骨な表現、危険なコンテンツなどの有害なコンテンツを含むかどうかを評価したスコアです。
LLM モデルを使用し、その生成された出力を評価することにより、安全性のスコアが求められます。安全性のスコアは 0(危険)~1(安全)の範囲で評価されます。 - フルフィルメント:
生成された出力が、要件や指示を含め、プロンプトの内容に正確に従っているかを評価したスコアです。
LLM モデルを使用し、その生成された出力を評価することにより、フルフィルメントのスコアが求められます。フルフィルメントのスコアは 1(最低)~5(最高)の範囲で評価されます。
- 一貫性:
- グラウンドトゥルースを有効化した場合
- ROUGE:
N グラムを使用して、生成された出力とグラウンド トゥルースの間で重複する最長共通部分列 の長さを測定し、結果を集約したスコアです。ROUGELsum は要約タスクの評価に適しています。 - BLEU:
生成された出力とグラウンド トゥルースとの類似性を N グラムを使用して評価したスコアです。
BLEU のスコアは 0(完全に不一致)~1(完全に一致)の範囲で評価され、一般的に 0.5 以上のスコアであれば高品質とみなされます。
- ROUGE:
4. 使い方
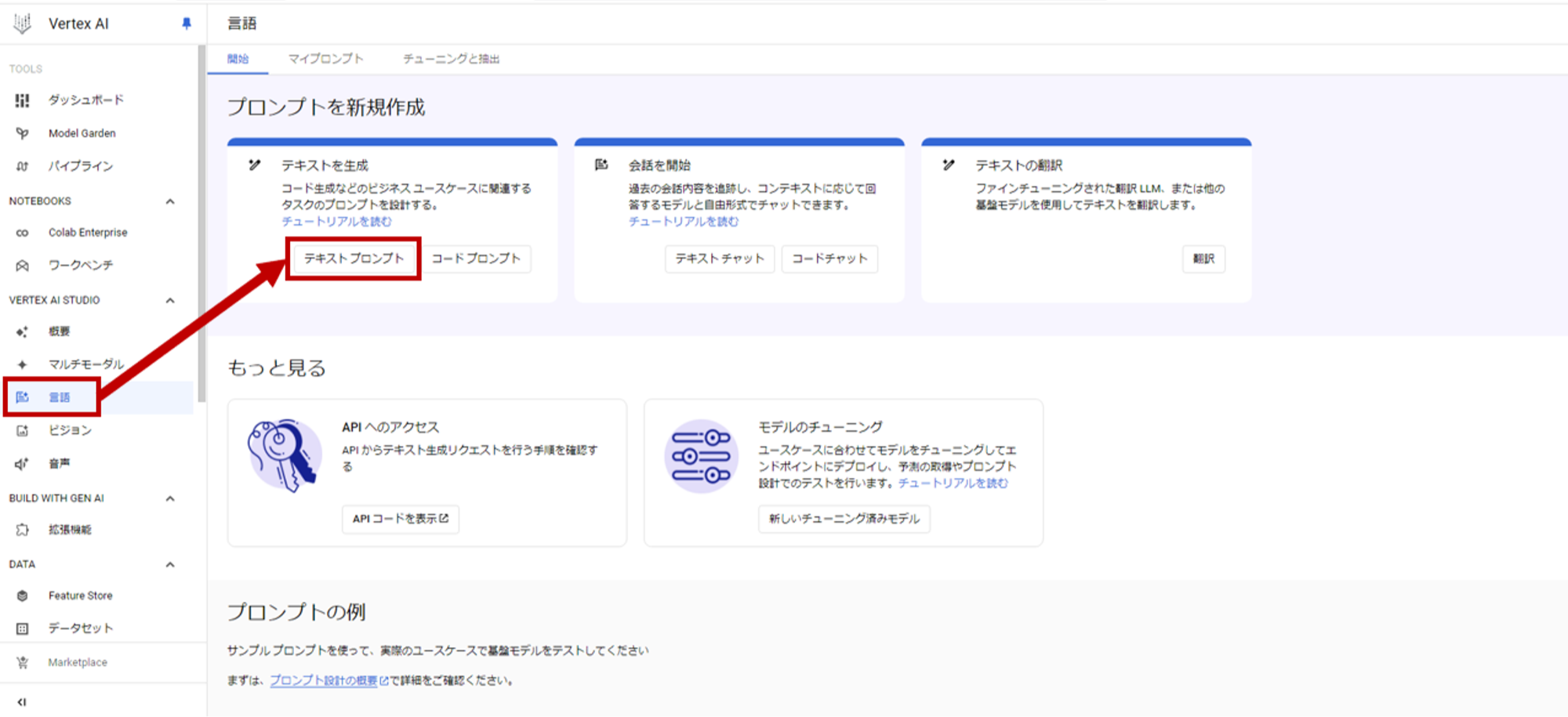
- VERTEX AI STUDIOへ移動します。 左のメニューから言語を選択して、テキストプロンプトを選択します。
- プロンプトを記述して、タイトルをつけて保存を押します。
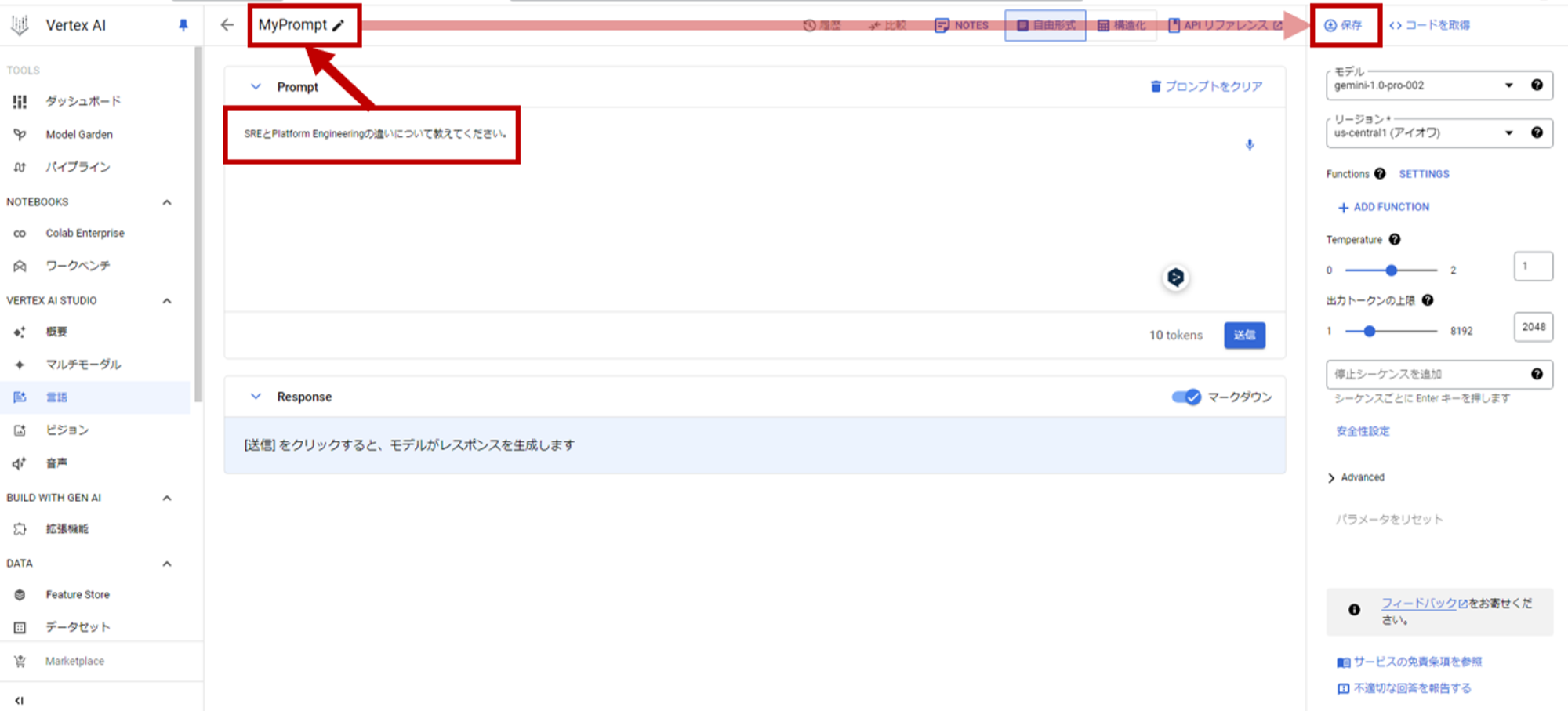
- Save promptのメニューが出るので保存します。
- 比較ボタンが押せるようになります。
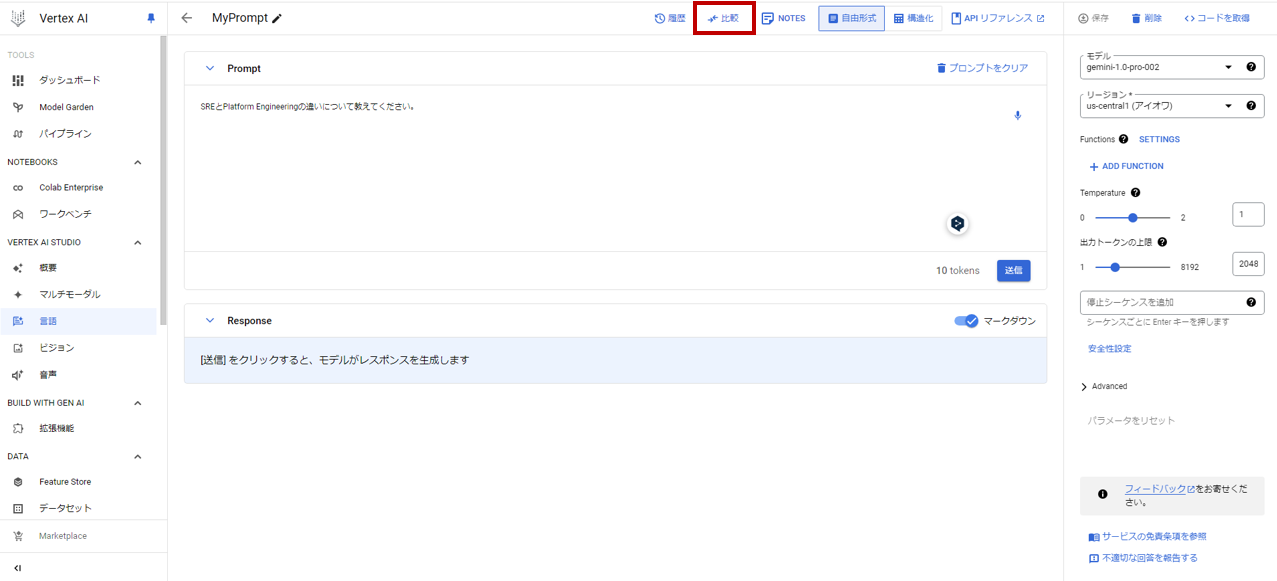
- 比較ページに遷移します。比較を押して、プロンプトを追加します。
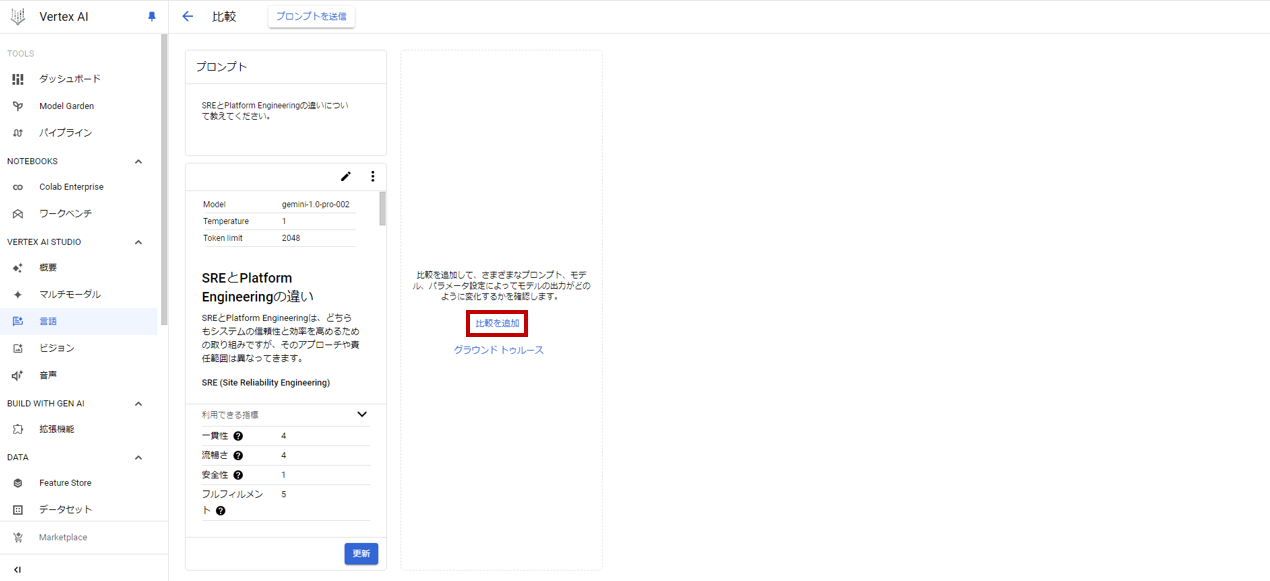
- プロンプト送信を押す事で、各プロンプトに関するレスポンスを得る事ができます。
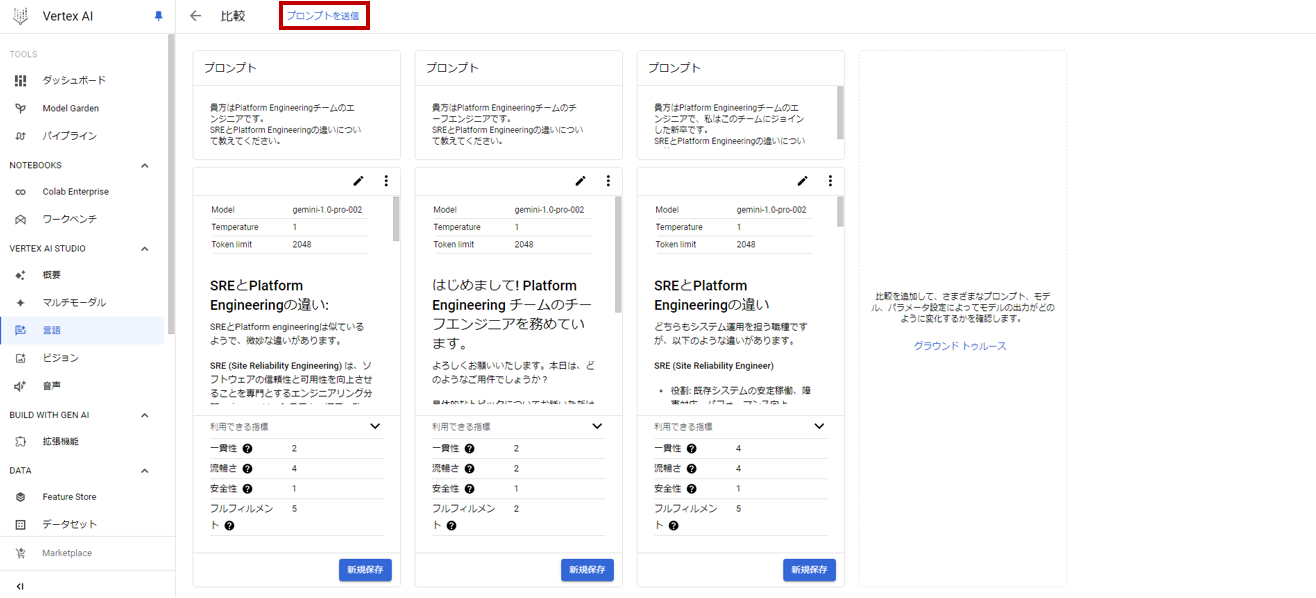
TIPS
比較ボタンを押すにはプロンプトの保存という工程が必要ですが、ココから一発で飛べます。
5. 所感
並列実行による自然言語モデルの出力結果を直接見れるだけでなく、定量的な指標に基づく評価から、堅牢なプロンプト設計が行えるため、より精度の高い出力や望む結果を得やすくなります。
また、このプロンプト比較機能は、ユーザーが自然言語モデルの挙動を理解し、その機能を最大限に活用するのに役立ちます。
6.おわりに
本記事では、Goole Cloudのプロンプト比較機能について調査しました。
引き続き、SREや生成AIに関する技術検証を続けていきます。