
本日お伝えしたいこと
あらゆるものが抽象化・仮想化されても、CPU やメモリの仕組みやプロトコルの性質などの計算機における基礎知識は持っておかないと調査がうまくいかない場面がある、ということです。
具体的なエピソードを交えて、お伝えしていこうと思います。
事の経緯
- EKS バージョンアップ (1.20→1.21) 検証中の出来事
- バージョンアップ後に、EKS 上で稼働するアプリで
readness probe, liveness probeがタイムアウトで頻繁に落ち、pod が立ち上がらなくなる事象が起きました。
レスポンスタイムにして 400ms → 1000ms ぐらいまでパフォーマンス低下が発生
→ タイムアウト1秒に頻繁に引っかかるようになり、色々試したところ CPU の Resource limit を修正することで、大幅改善しました。
CPU についてざっくりとおさらい
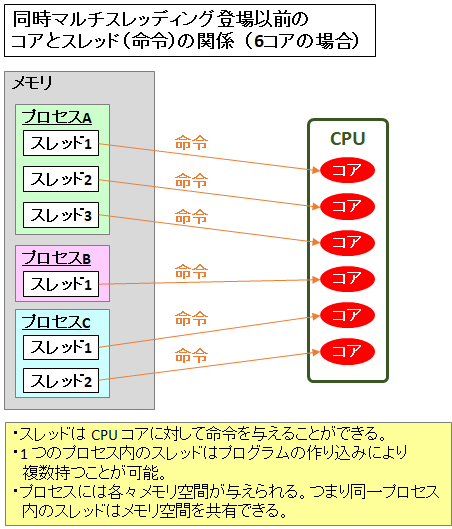
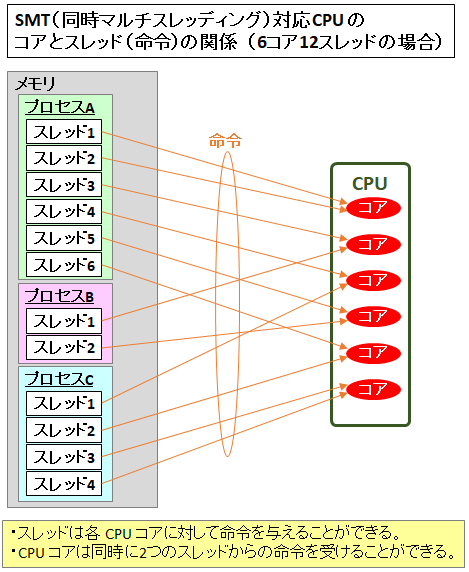
- コアは同時に複数の処理を実行することができない
でもマルチスレッドで並列処理できるんでしょ?
→ 並列処理に見えるだけで実態は並行処理で、高速で処理するスレッドを切り替えて疑似的に並列処理にしています。
Resource limit (CPU) の設定について
Kubernetes の公式ではこう記されていました。
CPU リソースの制限と要求は、cpu単位で測定されます。 Kuberenetes における1つの CPU は、クラウドプロバイダーの 1 vCPU/コア およびベアメタルのインテルプロセッサーの 1 ハイパースレッドに相当します。
https://kubernetes.io/ja/docs/concepts/configuration/manage-resources-containers/#meaning-of-cpu
要求を少数で指定することもできます。spec.containers[].resources.requests.cpuが0.5のコンテナは、1CPU を要求するコンテナの半分の CPU が保証されます。0.1という表現は100mという表現と同等であり、100ミリCPUと読み替えることができます。100ミリコアという表現も、同じことを意味しています。0.1のような小数点のある要求は API によって100mに変換され、1mより細かい精度は許可されません。 このため、100mの形式が推奨されます。
CPU は常に相対量としてではなく、絶対量として要求されます。0.1は、シングルコア、デュアルコア、あるいは 48 コアマシンのどの CPU に対してでも、同一の量を要求します。
https://kubernetes.io/ja/docs/concepts/configuration/manage-resources-containers/#how-pods-with-resource-limits-are-run
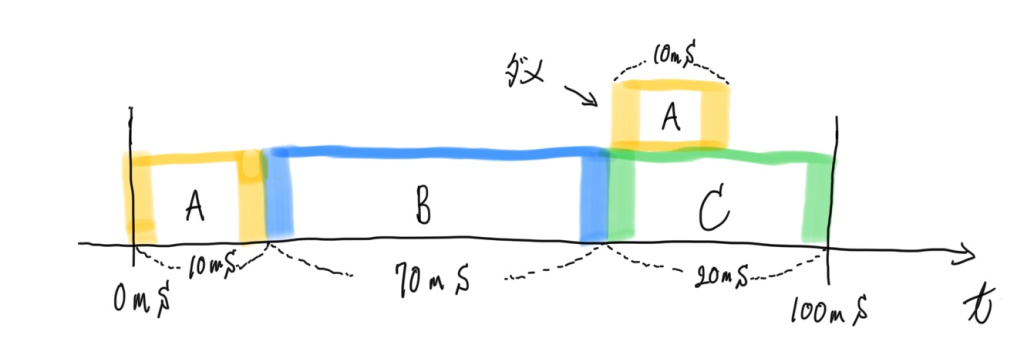
spec.containers[].resources.limits.cpuはミリコアの値に変換され、100倍されます。 結果の値は、コンテナが100ミリ秒ごとに使用できる CPU 時間の合計です。 コンテナは、この間隔の間、CPU 時間の占有率を超えて使用することはできません。
例えば 0.1 と設定した場合 0.1 * 100 = 10 となり、コンテナで実行されているプロセスについて 100ms の実行時間のうち 10ms が使用できる上限となります。
つまり、100ms のうち 10ms を使い果たした場合、次の 100ms まで待つ必要があります。
このような仕組みが前提にありつつ、弊社メンバーより以下のアドバイスをもらい本番適用前に対応することができました。
200m で limit をかけた場合、単位時間あたりに使える時間が 1/5 になります。(1000m core = 1coreなので 200/1000 = 1/5) ちょっと計算しては休まされ、ちょっと計算しては休まされという具合に。 CPU の Limit は重要じゃないコンテナが CPU を占拠してしまわないように設定する程度で。
まとめ
- CPU をケーキを分けるように分割して各プロセスに配布するかのような記載も散見されるが、実行時間について制限をかけているという意識を頭に入れておく必要があります。
当たり前ですが意味をちゃんと理解して設定しないと、期待した挙動をしないので注意が必要です。 - ここが適切に設定できていないと、ノードの CPU リソースを持て余したり、オーバーコミットする可能性があります。
すなわち、適切に設定できれば、今よりもリソース効率を高めて pod 数を減らすことができるケースがあります。 - もしアプリケーションごとに Namespace を分けているような設計の場合、
ResourceQuotaやLimitRangeも活用しやすいと思うので積極的に導入したいところです。
あとがき
ちなみに CPU の Resource request について、Google Cloud のブログ記事では以下のように書いていました。
Unless your app is specifically designed to take advantage of multiple cores (scientific computing and some databases come to mind), it is usually a best practice to keep the CPU request at ‘1’ or below, and run more replicas to scale it out. This gives the system more flexibility and reliability.
意訳: マルチコアを意識したアプリケーションでない限りは、CPU の Resource request は 1core (1000m core) 以下に設定して、レプリカを増やすのがベストプラクティスです。その方が柔軟性と信頼性の面で優れています。
また、Resource limit については以下のように書かれていました。
It’s when it comes to CPU limits that things get interesting. CPU is considered a “compressible” resource. If your app starts hitting your CPU limits, Kubernetes starts throttling your container. This means the CPU will be artificially restricted, giving your app potentially worse performance! However, it won’t be terminated or evicted. You can use a liveness health check to make sure performance has not been impacted.
意訳: CPU は圧縮可能なリソースだとされています。アプリが CPU リミットにあたり始めると Kubernetes は対象コンテナについてスロットリングします。これによってアプリパフォーマンスが低下する可能性があることを意味しています。ただし、コンテナ終了したり evict することはありません。パフォーマンスに影響があるかどうかの確認として livenessProbe を使用するのが有効です。
引用元: https://cloud.google.com/blog/products/containers-kubernetes/kubernetes-best-practices-resource-requests-and-limits