
1. はじめに
はじめまして、Sreake事業部の井上 秀一です。私はSreake事業部にて、SREや生成AIに関するResearch & Developmentを行っています。
本記事では、LLMの評価手法として利用できる、Google CloudのRapid evaluation APIについて調査しました。
2. Rapid evaluation APIとは
Rapid evaluation APIは、Google CloudのVertex AIプラットフォーム上で提供されるサービスであり、大規模言語モデル(LLMs)の評価を迅速に行うことができます。このサービスは、ポイントワイズとペアワイズ手法を利用した、複数の指標でLLMsを評価します。ここで、ポイントワイズとペアワイズとは、以下の手法を指します。
- ポイントワイズ(Pointwise)
- 単一の文章とクエリの関連性を評価します。具体的には、文書がクエリに関連しているかどうかをLLMに判断させ、その結果から関連性スコアを計算します。
- LLMへの入力例:
- クエリ: 猫の飼い方
- 文書: 猫は毎日新鮮な水を必要とします。
- プロンプト: この文書はクエリに関連していますか? ‘Yes’ または ‘No’ で答えてください。
- ペアワイズ(Pairwise)
- 2つの文書を比較し、どちらがクエリに対してより関連性が高いかを評価します。これにより、文書の相対的な関連性を判断します。
- LLMへの入力例:
- クエリ: 猫の飼い方
- 文書1: 猫は毎日新鮮な水を必要とします。
- 文書2: 猫は日光浴が好きです。
- プロンプト: どちらの文書がクエリに対してより関連性が高いですか? ‘文書1’ または ‘文書2’ で答えてください
Rapid evaluation APIでは、 text-bisonを利用して、評価タスクに特化したメトリクスを返します。例えば、LLMの出力と所望の出力の類似度をスコア化するRougeInput、レスポンスの安全性レベルを評価するSafetyInput、tools系(関数呼び出し機能)を評価するToolCallValidInput、ToolNameMatchInput、ToolParameterKeyMatchInput、ToolParameterKVMatchInputがあります。
主な機能とメトリクス
Rapid evaluation APIは、以下のような多様なメトリクスを提供します。
| 評価カテゴリ名 | 日本語対応 | 用途説明 |
|---|---|---|
| exact_match_input | 〇 | 予測が参照と完全に一致しているかどうかを評価するための入力 |
| bleu_input | 〇 | 予測と参照を比較して BLEU スコアを計算するための入力 |
| rouge_input | 〇 | 予測と参照を比較して ROUGE スコアを計算するための入力。rouge_type はさまざまな ROUGE スコアをサポートしています |
| fluency_input | × | 単一レスポンスの回答の言語習熟度を評価するための入力 |
| coherence_input | × | 単一のレスポンスが、一貫性があり、わかりやすい内容の返信を行うことができるかどうかを評価するための入力 |
| safety_input | 〇 | 単一レスポンスの安全性レベルを評価するための入力 |
| groundedness_input | 〇 | 単一のレスポンスが、入力テキストにのみ含まれる情報を提供または参照できるかどうかを評価するための入力 |
| fulfillment_input | 〇 | 単一のレスポンスが指示内容の要件を完全に満たすことができるかどうかを評価するための入力 |
| summarization_quality_input | 〇 | 全般的に見て単一レスポンスがどの程度適切にテキストを要約できるかを評価するための入力 |
| pairwise_summarization_quality_input | 〇 | 2 つのレスポンスの全般的な要約の品質を比較するための入力 |
| summarization_helpfulness_input | 〇 | 単一レスポンスが、元のテキストを置き換えるために必要な詳細情報を含む要約を提供できるかどうかを評価するための入力 |
| summarization_verbosity_input | 〇 | 単一のレスポンスが簡潔な要約を提示できるかどうかを評価するための入力 |
| question_answering_quality_input | 〇 | 全般的に見て、参照するテキスト本文が与えられたときに、単一のレスポンスがどの程度質問に回答できるかを評価するための入力 |
| pairwise_question_answering_quality_input | 〇 | 全般的に見て、参照するテキスト本文が与えられたときに、2 つのレスポンスがどの程度質問に回答できるかを比較するための入力 |
| question_answering_relevance_input | 〇 | 質問に対して単一のレスポンスが関連する情報で応答できるかどうかを評価するための入力 |
| question_answering_helpfulness_input | 〇 | 質問に答える際に単一のレスポンスが重要な詳細情報を提供できるかどうかを評価するための入力 |
| question_answering_correctness_input | 〇 | 単一のレスポンスが質問に正しく答えられるかどうかを評価するための入力 |
| tool_call_valid_input | 〇 | 単一のレスポンスが有効なツール呼び出しを予測できるかどうかを評価するための入力 |
| tool_name_match_input | 〇 | 単一のレスポンスがツール呼び出しを正しいツール名で予測できるかどうかを評価するための入力 |
| tool_parameter_key_match_input | 〇 | 単一のレスポンスが、正しいパラメータ名でツール呼び出しを予測できるかどうかを評価するための入力 |
| tool_parameter_kv_match_input | 〇 | 単一のレスポンスが、正しいパラメータ名と値でツール呼び出しを予測できるかどうかを評価するための入力 |
3. 利用する上での注意点・問題点
注意点
Rapid evaluation APIにおけるリージョン(Region)の指定方法が、サブドメインに記述する方式のため、リージョン(Region)の設定ミスをすると容赦なく404レスポンスになります。
uri = f"https://{self.__REGION}-aiplatform.googleapis.com/v1beta1/projects/{self.__PROJECT_ID}/locations/{self.__REGION}:evaluateInstances"問題点
Rapid evaluation APIは有用なツールですが、記事執筆時点(2024年5月31日)で、以下の問題を抱えています。
1.一部のRapid evaluation APIは、日本語の入力に対応していません。以下はfluency_inputの出力です。
# fluency_input: 単一レスポンスの回答の言語習熟度を評価するための入力
# 日本語を入力した場合
{
"fluencyResult": {
"score": 1,
"explanation": "The response is written in Japanese, which is not the language being assessed.",
"confidence": 1,
}
}
# 英語を入力した場合
{
"fluencyResult": {
"score": 4,
"explanation": "The response demonstrates a good understanding of grammar rules, with no major errors in sentence structure, verb usage, subject-verb agreement, punctuation, or capitalization.",
"confidence": 0.8,
}
}2.公式ドキュメントで示されているレスポンスと、実際のレスポンスが異なる。
公式ドキュメントによれば、いずれのAPIのレスポンスも、キーがスネークケースで構成されています。
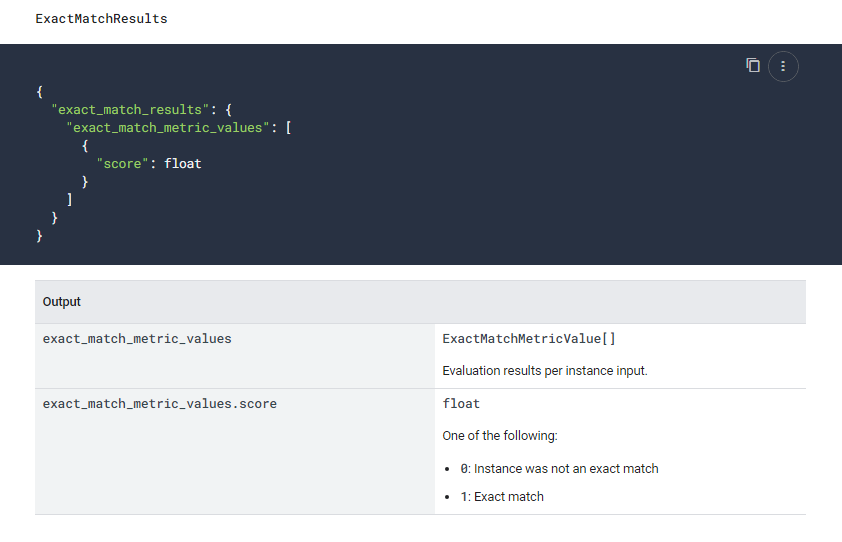
しかし実際のレスポンスでは、キー名がローワーキャメルケースで構成されています。バリデーションチェックを行う場合は、この点に留意する必要があります。
{
"exactMatchResults": {
"exactMatchMetricValues": [
{
"score": 1,
}
]
}
}3.公式ドキュメントで示されているTool系の入力ペイロードに誤りがある。
- 対象
ドキュメントではinstanceと書かれているので、その通りに実行するとエラーがレスポンスされます。
# ドキュメント通りにした例
tool_name_match_input = {
"tool_name_match_input": {
"metric_spec": {},
"instance": {
"prediction": jsonargs,
"reference": jsonargs,
},
}
}
# 出力
{
"error": {
"code": 400,
"message": "Invalid JSON payload received. Unknown name \"instance\" at 'tool_name_match_input': Cannot find field.",
"status": "INVALID_ARGUMENT",
"details": [
{
"@type": "type.googleapis.com/google.rpc.BadRequest",
"fieldViolations": [
{
"field": "tool_name_match_input",
"description": "Invalid JSON payload received. Unknown name \"instance\" at 'tool_name_match_input': Cannot find field.",
}
],
}
],
}
}instancesに修正すると、以下の様に正常に動作します。
# instancesに修正
tool_name_match_input = {
"tool_name_match_input": {
"metric_spec": {},
"instances": {
"prediction": jsonargs,
"reference": jsonargs,
},
}
}
# 出力
{
"toolNameMatchResults": {
"toolNameMatchMetricValues": [
{
"score": 1,
}
]
}
}こちらの問題は私のメンターである佐藤さんが、解決に導いてくれました。
4. Rapid evaluation APIのハンズオン
この章では、3つのRapid evaluation APIと、Python 3.10.12を利用して実際にレスポンスを得るためのハンズオンを行います。以下はPythonからRapid evaluation APIを利用するためのサンプルコードです。
- RapidEvaluationAPI.py
# RapidEvaluationAPI.py
from google import auth
from google.auth.transport import requests as google_auth_requests
class RapidEvaluationAPI:
"""Rapid Evaluation APIを利用するためのクラス"""
__URL: str = "https://www.googleapis.com/auth/cloud-platform"
__PROJECT_ID: str = None
__REGION: str = None
__CREDENTIAL: str = None
def __init__(self, project_id: str, region: str) -> None:
self.__PROJECT_ID = project_id
self.__REGION = region
self.__check()
self.__CREDENTIAL = self.__auth()
def __auth(self) -> None:
"""Google Cloudの認証を行う処理"""
credential, _ = auth.default(scopes=[self.__URL])
return credential
def run_evaluation(self, data: dict) -> dict:
"""評価を実行する
Args:
data (dict): Rapid evaluation APIを利用する際のペイロード
Returns:
dict: Rapid evaluation APIからのレスポンス
"""
uri = f"https://{self.__REGION}-aiplatform.googleapis.com/v1beta1/projects/{self.__PROJECT_ID}/locations/{self.__REGION}:evaluateInstances"
result = google_auth_requests.AuthorizedSession(self.__CREDENTIAL).post(
uri, json=data
)
if result.status_code != 200:
print("", file=sys.stderr)
result.raise_for_status()
return dict(result.json())
def __check(self):
if self.__PROJECT_ID is None:
raise self.EnvironmentVariableError(
'Google Cloud ProjectID is None. Check env values "GCP_PROJECT_ID"'
)
if self.__REGION is None:
raise self.EnvironmentVariableError(
'Google Cloud Region is None. Check env values "GCP_PROJECT_ID"'
)
class EnvironmentVariableError(Exception):
def __init__(self, message):
super().__init__(message)
A. ハンズオン: FluencyInput
このハンズオンでは、特定の入力テキストに基づいて生成された、単一のレスポンスの言語習熟度(文法や流暢さ)を評価するためのfluency_inputを利用します。
# main.py
if __name__ == "__main__":
import pprint
# RapidEvaluationAPIの利用に必要な情報を入れる
rapidEvaluationAPI = RapidEvaluationAPI(
project_id="YOUR PROJECT ID",
region="us-central1",
)
# fluency_inputで評価する文章
text = "Vertex AI offers access to Gemini models from Google. Gemini is capable of understanding virtually any input, combining different types of information, and generating almost any output. Prompt and test in Vertex AI with Gemini, using text, images, video, or code. Using Gemini’s advanced reasoning and state-of-the-art generation capabilities, developers can try sample prompts for extracting text from images, converting image text to JSON, and even generate answers about uploaded images to build next-gen AI applications."
# fluency_inputを利用するためのペイロード
fluency_input_data = {
"fluency_input": {
"metric_spec": {},
"instance": {"prediction": text},
}
}
# 評価を実行
response = rapidEvaluationAPI.run_evaluation(data=fluency_input_data)
# 評価結果
pprint.pprint(response)main.pyを実行すると、以下のような結果が得られます。
{
"fluencyResult": {
"confidence": 0.8,
"explanation": "The response has a few grammatical errors, "
'such as "Prompt and test in Vertex AI with '
"Gemini, using text, images, video, or "
'code." should be "Prompt and test in Vertex '
"AI with Gemini using text, images, videos, "
'or code."',
"score": 4,
}
}ここで、fluency_inputに対するレスポンス項目は、次のように定義されています。
| 出力 | |
|---|---|
score | float: 次のいずれかです。• 1: 不整合 • 2: やや不整合 • 3: どちらともいえない • 4: やや一貫性がある • 5: 一貫性がある |
explanation | string: スコア割り当ての根拠。 |
confidence | float: 結果の信頼スコア([0, 1])。 |
B. ハンズオン: GroundednessInput
このハンズオンでは、特定の入力テキストに基づいて生成された単一のレスポンスが、与えられた情報をどの程度正確に反映または参照しているかを評価します。この評価は、LLMに関連情報を組み込む手法、例えばRAG(Retrieval-Augmented Generation)を用いている場合に役立ちます。このプロセスを通じて、モデルがどれだけ効果的に情報を取り込み、適切な回答を生成するかを検証します。
if __name__ == "__main__":
import json
import pprint
# RapidEvaluationAPIの利用に必要な情報を入れる
rapidEvaluationAPI = RapidEvaluationAPI(
project_id="gen-ai-lab-391309",
region="us-central1",
)
# LLMへの入力LLM レスポンスで使用できるすべての情報が含まれています。
context = """
# Input
SREって何?
# Embedded information
SRE(Site Reliability Engineering)とは、元々Googleが提唱したシステム管理とサービス運用に対するアプローチです。SREの特長は、信頼性をシステムの重要な機能の1つと位置づけている点です。SREでは、サイトやサービスの信頼性を向上させるため、コードによって手作業や繰り返し行われる作業(トイル)を減らしたり、システムを自動化して作業量の増大に対応することを重視しています。
"""
# LLMからの出力
prediction = "SREはSite Reliability Engineeringのことです。"
# groundedness_inputを利用するためのペイロード
groundedness_input = {
"groundedness_input": {
"metric_spec": {},
"instance": {
"prediction": prediction,
"context": context,
},
}
}
# 評価を実行
response = rapidEvaluationAPI.run_evaluation(data=groundedness_input)
# 評価結果
pprint.pprint(response)
print(response)
main.pyを実行すると、以下のような結果が得られます。
{
"groundednessResult": {
"score": 1,
"explanation": "The response provides the full name of SRE, which is Site Reliability Engineering. This information is explicitly mentioned in the context.",
"confidence": 1,
}
}ここで、groundedness_inputに対するレスポンス項目は、次のように定義されています。これは、単一のレスポンスが、入力テキストにのみ含まれる情報を提供または参照できるかどうかを評価するための評価手法です。従って、contextに含まれている情報のみで、predictionが構成されていれば、スコアは1になります。
| 出力 | |
|---|---|
score | float: 次のいずれかです。• 0: 根拠なし • 1: 根拠あり |
explanation | string: スコア割り当ての根拠。 |
confidence | float: 結果の信頼スコア([0, 1])。 |
逆にcontextに示されていない情報が、predictionに含まれていた場合、次のようにscoreが0になります。
# LLMへの入力LLM レスポンスで使用できるすべての情報が含まれています。
context = """
# Input
SREって何?
# Embedded information
3-shakeはインフラレイヤーの技術力を武器に、リアルタイムビックデータ処理、アドテクノロジーのプラットフォームサービスを提供しています。
"""
# LLMからの出力
prediction = "SREはSite Reliability Engineeringのことです。"
# 出力
{
"groundednessResult": {
"score": 0,
"explanation": "The response provides a definition of SRE, which is not included in the context.",
"confidence": 1,
}
}C. ハンズオン: ToolNameMatchInput
このハンズオンでは、単一のレスポンスがツール呼び出しを正しいツール名で予測できるかどうかを評価するため、tool_name_match_inputを利用します。
# main.py
if __name__ == "__main__":
import json
import pprint
# RapidEvaluationAPIの利用に必要な情報を入れる
rapidEvaluationAPI = RapidEvaluationAPI(
project_id="gen-ai-lab-391309",
region="us-central1",
)
# prediction (LLMからの出力)
prediction = {
"content": "",
"tool_calls": [
{
"name": "CheckServerStatus",
"arguments": {
"status": "Server is Online.",
},
}
],
}
# reference (所望の出力)
reference = {
"content": "",
"tool_calls": [
{
"name": "CheckServerStatus",
"arguments": {
"status": "Server is online.",
},
}
],
}
jsonargs = json.dumps(prediction)
# tool_name_match_inputを利用するためのペイロード
tool_name_match_input = {
"tool_name_match_input": {
"metric_spec": {},
"instances": {
"prediction": json.dumps(prediction),
"reference": json.dumps(reference),
},
}
}
# 評価を実行
response = rapidEvaluationAPI.run_evaluation(data=tool_name_match_input)
# 評価結果
pprint.pprint(response)main.pyを実行すると、以下のような結果が得られます。
{
"toolNameMatchResults": {
"toolNameMatchMetricValues": [
{
"score": 1,
}
]
}
}ここで、ToolNameMatchInputのレスポンスは、次のように定義されています。単一のレスポンスがツール呼び出しを正しいツール名で予測できるかどうかを評価するものです。従って、toolのnameが同じであればスコア1となります。
| 出力 | |
|---|---|
tool_name_match_metric_values | 繰り返し ToolNameMatchMetricValue: インスタンス入力ごとの評価結果。 |
tool_name_match_metric_values.score | float: 次のいずれかです。• 0: ツールの呼び出し名が参照と一致していません。 • 1: ツールの呼び出し名が参照と一致しています。 |
逆にtoolのnameに差が発生すると以下のようにscoreが変動します。
# prediction (LLMからの出力)
prediction = {
"content": "",
"tool_calls": [
{
"name": "ServerStatus", # CheckServerStatus -> ServerStatus
"arguments": {
"status": "Server is Online.",
},
}
],
}
# reference (所望の出力)
reference = {
"content": "",
"tool_calls": [
{
"name": "CheckServerStatus",
"arguments": {
"status": "Server is online.",
},
}
],
}
# レスポンス
{
"toolNameMatchResults": {
"toolNameMatchMetricValues": [
{
"score": 0,
}
]
}
}5. 所感
3章で指摘した問題点を除けば、Rapid evaluation APIは、LLMやLLMを用いたアプリケーションの検証や開発、RAG(Retrieval-Augmented Generation)を用いたLLM等で、定量的・客観的な評価指標として、開発プロセスの改善に寄与すると考えます。
6. おわりに
本記事では、Rapid evaluation APIについて調査しました。
引き続き、SREや生成AIに関する技術検証を続けていきます。