
istio の sidecar である pilot-agent, envoy が Pod の終了時にどう振る舞うのかをまとめてみました。
デフォルトの istio-proxy
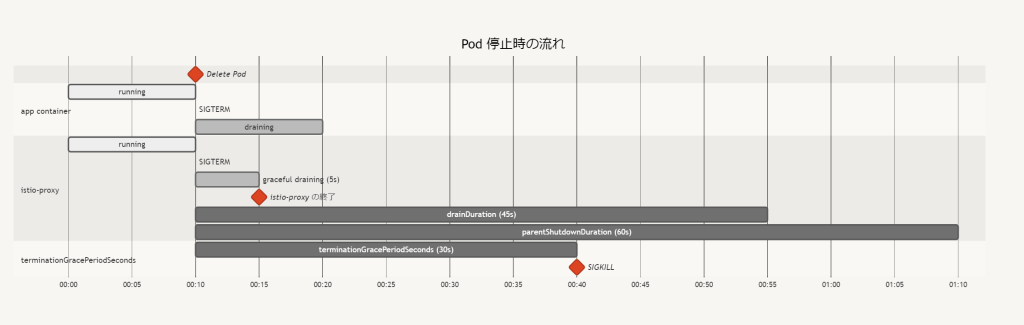
- Pod Delete されたタイミングで各コンテナに SIGTERM が送られる
- アプリコンテナが SIGTERM を受け取った場合の挙動は実装依存
- istio-proxy は Envoy を graceful drain モードにした上で terminationDrainDuration (default 5s) 待って終了する
- Envoy は graceful drain 中も新規接続を受け付け、HTTP/1.1 では Response のヘッダーに
Connection: closeをセットしてくれたり HTTP2 では GOAWAY を返してくれたりする - アプリコンテナの終了よりも先に istio-proxy (Envoy) が終了してしまうと、クライアント↔︎アプリ間やアプリ↔︎DB間との通信も切断されてしまう
- Graceful drain 時間は
terminationDrainDuration(default 5s) 設定で調整可能
preStop hook で main container の listener port の close を待つパターン
istio-proxy の preStop hook に次のような script を設定して、TCP Port を Listen しているプロセスがいなくなるまで istio-proxy への SIGTERM を遅らせるという hack が行われている場合の例です。
while [ $(netstat -plunt | grep tcp | grep -v envoy | wc -l | xargs) -ne 0 ]; do sleep 1; done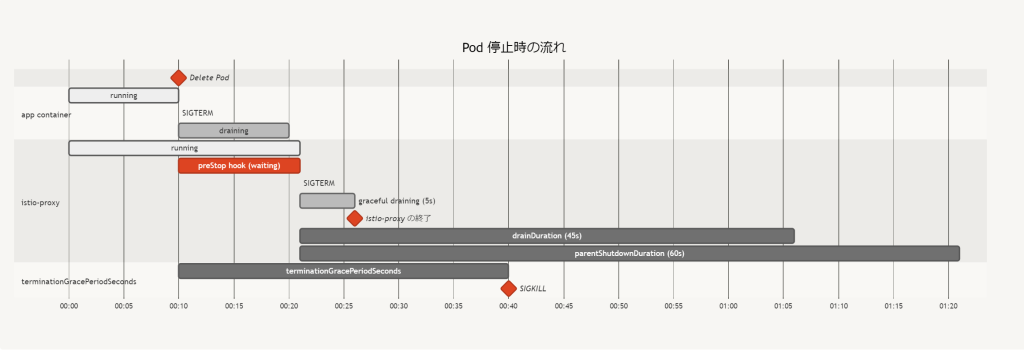
- アプリが終了時に必要な処理を完了した後に listen port を close する場合は istio-proxy が先に終了しているということが発生しない
- 処理中の connection 以外は port の listen も含め、すぐに close してしまう nginx のような場合は効果がなく、
terminationDrainDuration(default 5s) を調整する必要がある
EXIT_ON_ZERO_ACTIVE_CONNECTIONS を有効にした場合
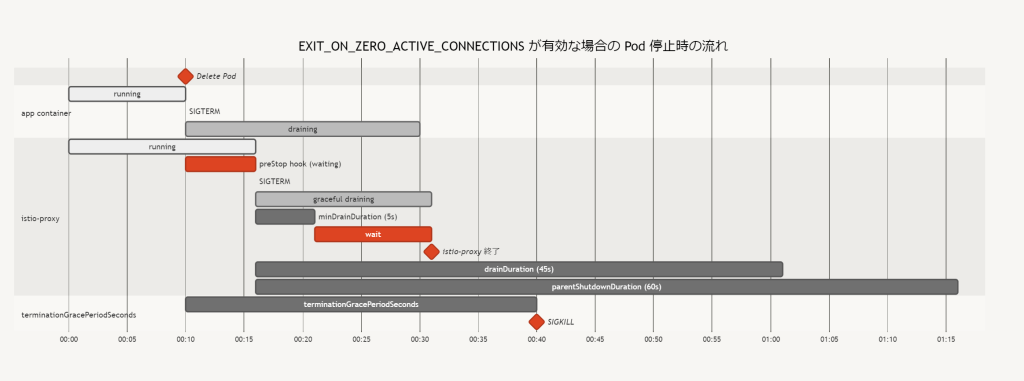
EXIT_ON_ZERO_ACTIVE_CONNECTIONSを有効にした場合、istio-proxy は Envoy を Graceful drain モードにした後、minDrainDuration(default 5s) 待ってから envoy のdownstream_cx_activeメトリクスを毎秒監視して 0 になるまで待機するEXIT_ON_ZERO_ACTIVE_CONNECTIONSを有効にするなら preStop hook はなくても良いminDrainDuration中に新規のリクエストが来ないようになっていないと active connection 0 を確認した直後に増える可能性がある
→ Service の Endpoint からの削除や istio の EDS 反映が終わること
→ クラスタ外の Load Balancer を使用している場合はそこから外れていること (istio-ingressgateway)
Drain 中の healthcheck
istio-proxy (pilot-agent) が Envoy を drain モードにした後は 15021 port の /healthz/ready は 503 を返すようになります。(Load Balancer からは早く外れたいのでこれは望ましい設定だと思われる)
この healthcheck 用 endpoint は Envoy が 15021 port で受けた後に pilot-agent の 15000 port に転送し、そこで既に drain 中かどうかや Envoy の stats を確認しているので、Envoy も istio-pilot も生きているかどうかの確認になっています。
istio-proxy の healthcheck
istio-proxy の healthcheck endpoint で行われていることの紹介です。
前提
istio-proxy は pilot-agent が Envoy を管理しており、どちらのプロセスも機能している必要がある
istio-proxy を監視する際に指定している 15021 port の /healthz/ready は何をやっているのか?
- 15021 port を Listen しているのは Envoy
そのため Envoy が死んだら healthcheck も失敗する - 15021 port で受けた
/healthz/readyは agent cluster に proxy される
agent cluster の endpoint は 127.0.0.1:15020 となっており、これは pilot-agent が Listen している portpilot/cmd/pilot-agent/status/ready/probe.goでhttp://127.0.0.1:15000/stats?usedonly&filter=^(server\.state|listener_manager\.workers_started)にアクセスして Envoy が機能していることを確認している (起動するまでだけ) - Listener
"static_resources": {
"listeners": [
{
"address": {
"socket_address": {
"address": "0.0.0.0",
"port_value": 15021
}
},
"filter_chains": [
{
"filters": [
{
"name": "envoy.filters.network.http_connection_manager",
"typed_config": {
"@type": "type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager",
"stat_prefix": "agent",
"route_config": {
"virtual_hosts": [
{
"name": "backend",
"domains": [
"*"
],
"routes": [
{
"match": {
"prefix": "/healthz/ready"
},
"route": {
"cluster": "agent"
}
}
]
}
]
},
"http_filters": [
{
"name": "envoy.filters.http.router",
"typed_config": {
"@type": "type.googleapis.com/envoy.extensions.filters.http.router.v3.Router"
}
}
]
}
}
]
}
]
}
]
- Cluster
"clusters": [
{
"name": "agent",
"type": "STATIC",
"connect_timeout": "0.250s",
"load_assignment": {
"cluster_name": "agent",
"endpoints": [
{
"lb_endpoints": [
{
"endpoint": {
"address": {
"socket_address": {
"address": "127.0.0.1",
"port_value": 15020
}
}
}
}
]
}
]
}
},
...
]
Pod 起動時のコンテナ起動順序問題
Pod から出ていく通信も Envoy を経由するようになるため、起動時にもメインのアプリより先に istio-proxy が起動してくれていないと困ります。
これは kubelet が Pod manifest の containers に書かれた順に container を起動させ、postStart hook があると、それの実行が完了してから次の container に進むという仕様を利用して sidecar injection で istio-proxy をメインのコンテナよりも先に挿入し、postStart hook で pailot-agent wait コマンドを実行して istio-proxy の完了を待つようにする設定項目があるためこれを有効にします。(holdApplicationUntilProxyStarts で検索)