[Kubecon EU 2024: Cloud Native AI Day]Reducing Cross-Zone Egress at Spotify with Custom gRPC Load Balancing のご紹介

はじめに
こんにちは、Sreake事業部の永瀬滉平です!
今回はKubeCon EU 2024に参加してきましたので、中でも気になったセッションをピックアップしてご紹介したいと思います。
セッションについて
取り上げるセッションは以下です。
Reducing Cross-Zone Egress at Spotify with Custom gRPC Load Balancing
訳: Spotify社におけるカスタムgRPCロードバランシングを用いたクロスゾーンEgressトラフィックの削減
以降でセッションの詳細をお話ししますが、一部スライドを引用してご説明します。
Spotify社での課題感
みなさんご存知のSpotifyというサービスはクラウド上にマイクロサービスアーキテクチャで構築されています。
クラウドでは”リージョン”と”ゾーン”というロケーションについての概念があります。リージョンは、例えば東京・大阪、アメリカはオレゴン・バージニアなどのような単位で、ゾーンはこれら各リージョン内でのいくつかのデータセンターの固まりとして分割される単位です。Google Cloudであれば”ゾーン”、AWSであれば”アベイラビリティゾーン”と呼ばれ、ゾーン間通信に料金が課されます。 Spotifyのような大規模サービスでは、たくさんのサービス間で大量の通信が行われておりもちろんゾーンを跨ぐ通信もたくさんあります。具体的には、サービス間通信の実に約70%がゾーン間通信であり、これがコスト要因として問題視されていました。
通信プロトコルとしてはgRPCがすでに広く使われていましたので、この課題に対してgRPCを拡張してクライアントサイドロードバランシングを実装したという内容のセッションでした。
gRPCについて
gRPCはオープンソースのRPC(Remote Procedure Call)フレームワークです。HTTP/2をベースとしており、双方向ストリーミングや認証やロードバランシングなどの処理を差し込むことができるという特徴があります。 ユースケースとしても、バックエンドサーバーやモバイルデバイスなど幅広い領域で使用されています。
このgRPCでは、いくつかのロードバランシングアルゴリズムが使用できます(※ライブラリや言語によって異なります)。
- ラウンドロビン
- 重み付けラウンドロビン
- Least Request
- …etc
また、独自のロードバランシングアルゴリズムを組み込むこともできるとともに、バックエンドサーバーから独自メトリクスを収集して転送できるよう実装する余地もあります。
参考:
Spotify社でのロードバランシング要件
大きく2点あります。
- 基本的には同一ゾーン内での通信とすること
- 料金分の効果が見込めるシチュエーションにおいては、ゾーン間通信を許容すること
2番については、レイテンシーが少ない場合があります。具体的な例として、下図のようにゾーンAにあるクライアントから発せられるリクエストについて考えて見たいと思います。
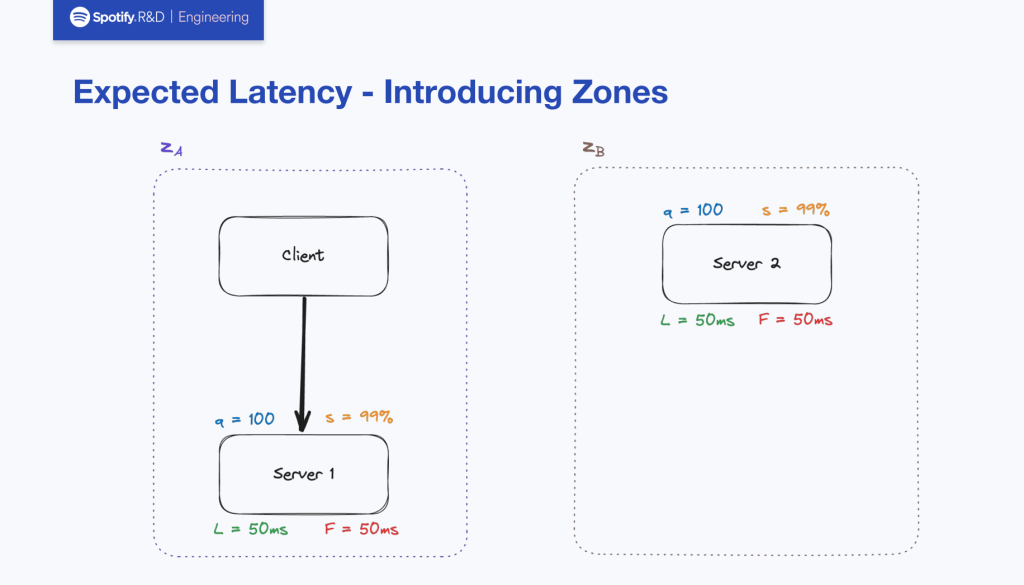
server1とserver2ではレイテンシーやエラー率などの条件が一緒になっています。この場合は要件1番に照らし合わせて、server1にルーティングすることになります。
しかし、server2のサクセスレイテンシー(L)が10倍だけserver1よりも良い状態においてはユーザビリティ向上に寄与することでゾーン間通信の料金分をペイできる効果があるとして、要件2番に照らし合わせてserver2にルーティングします。
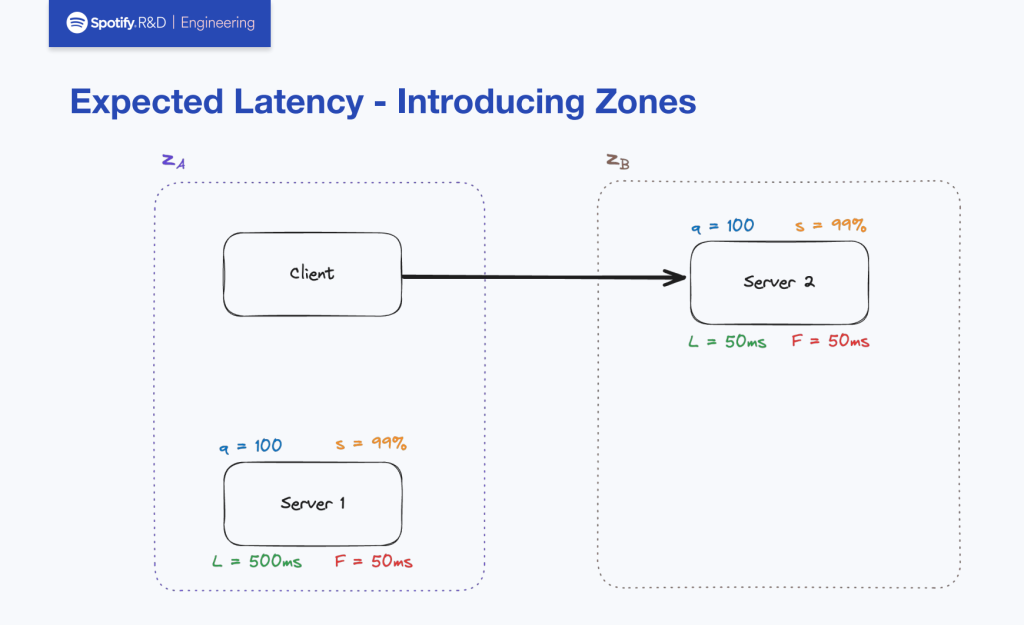
以降、このような要件を満たすためのロードバランシングアルゴリズムについて説明します。
ロードバランシングアルゴリズムについて
ロードバランシングアルゴリズムのコンセプトは、過去のRPCのレイテンシーをベースに予測されるレイテンシーを計算して最もレイテンシーが少ないと予測されるサーバーにルーティングするというものです これのコンセプトおよび導き出されたレイテンシーを”Expected Latency”と呼んでおり、以降の説明では記号Eとして具体的なアルゴリズムの説明をします。
サーバーのサクセスレートが100%の場合
まずは単純な例としてサーバーのサクセスレートが100%の場合から考えてみます。
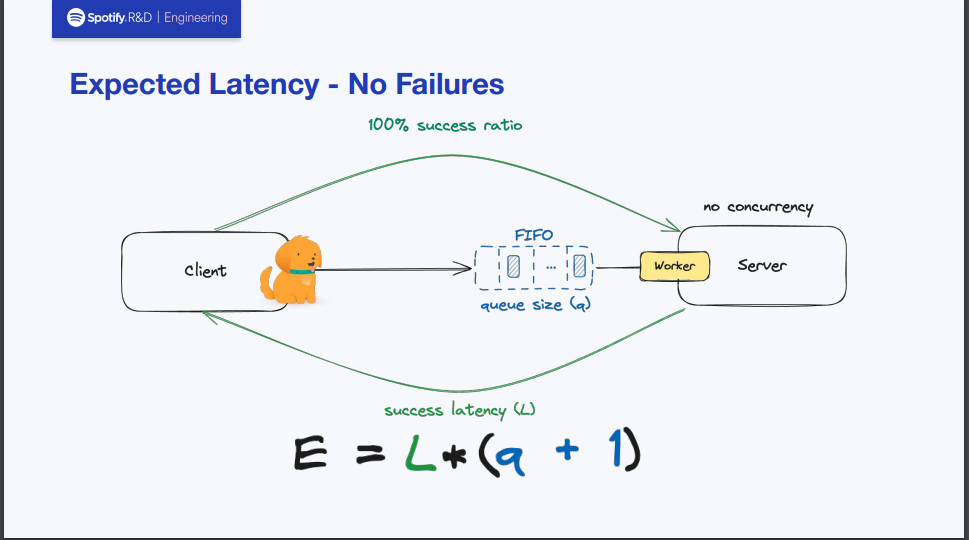
まず前提として、サーバーにはFIFOキューが張り付いており、ここに送信されてきたリクエストが一旦キューイングされるようなシステムであるとします。
サクセスレートが100%ですから、もちろんエラーが発生していないことを意味しています。 したがって、1つ当たりのリクエストを捌くときのレイテンシーLにキューのサイズaとリクエスト送信した当のClient分1を加えたものをかけるだけでEが求められます。
これはとても直感的なものかと思います。
サーバーのサクセスレートが50%の場合
次にサクセスレートが50%の場合を考えてみます。すなわち先ほどと違って、リクエスト捌く際に失敗が生じている状況を意味します。
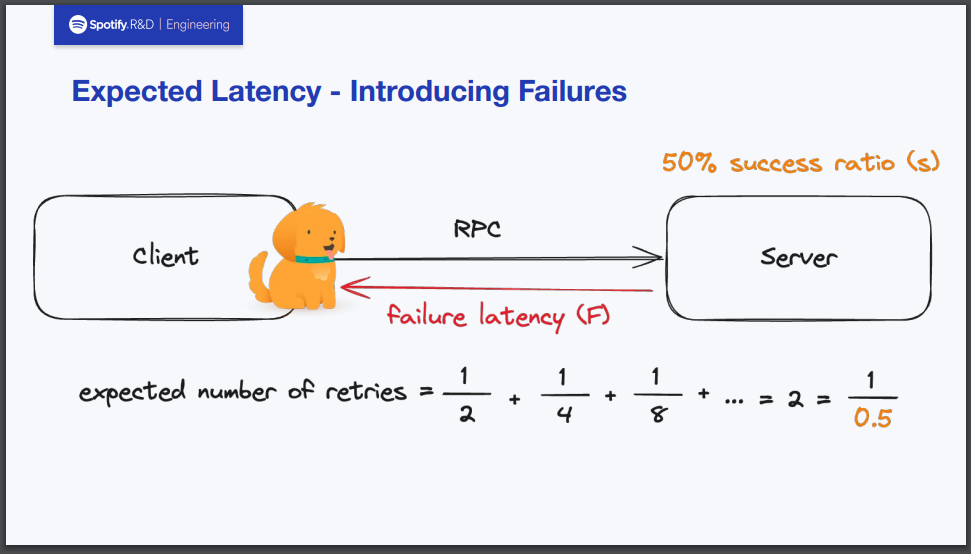
失敗時のレイテンシーはFとおきます。失敗時はリトライが発生しますから、リトライの回数の期待値をサクセスレートから求める必要があります。今回の場合、50%の確率でリトライが発生することがわかっているので、求める期待値は1/0.5=2となります。
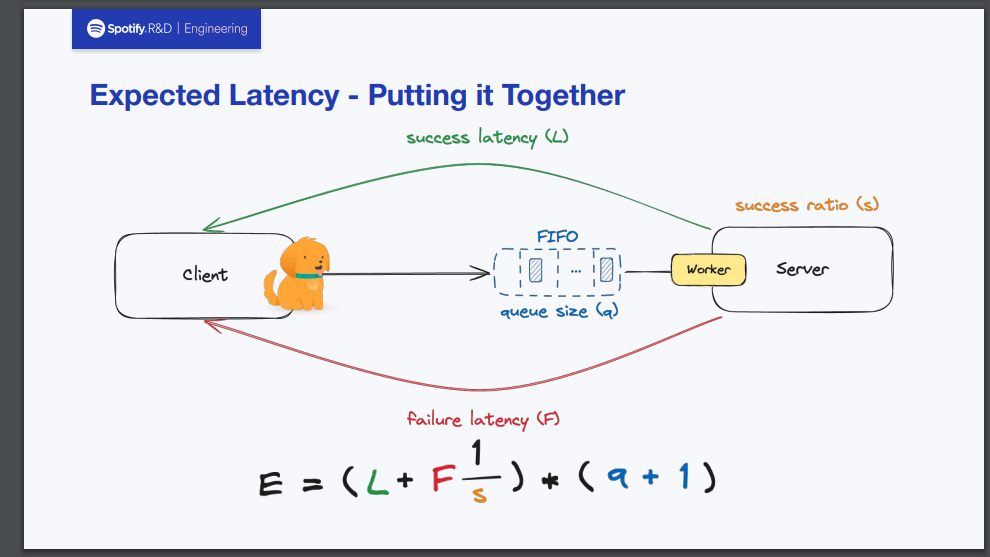
ここからEを求めますが、サクセスレート100%時の式にF*1/sというのがレイテンシーとして足し算される形になります。これを言語化すると、「1つのリクエストを処理するときに失敗時のレイテンシーが予測されるリトライ回数分だけ繰り返される」と言えます。
ゾーン間通信の重み付けを取り込む
ここまでで改良を重ねてきたEを求める公式に対して、肝となるゾーン間通信によるペナルティを導入します。
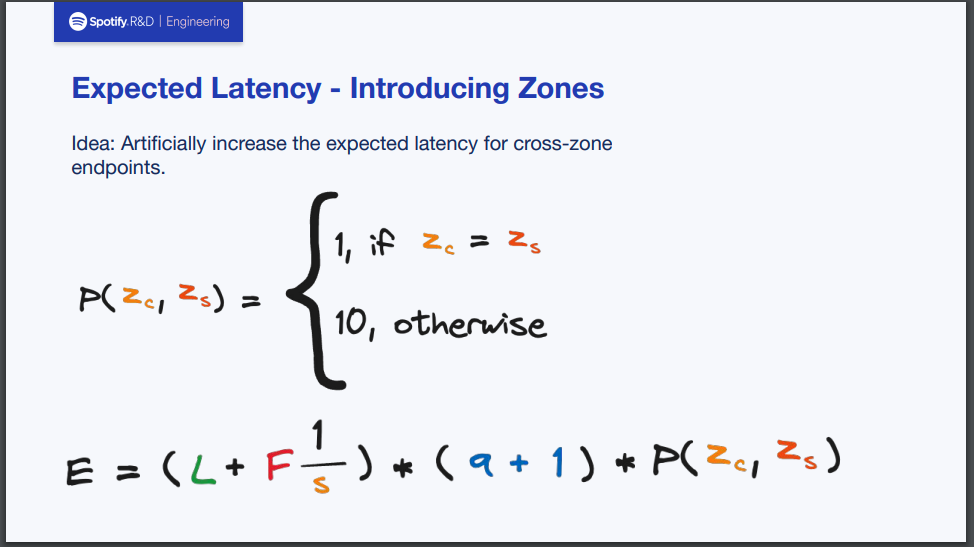
まず、ペナルティPはZc(クライアントが存在するゾーン)とZs(サーバーが存在するゾーン)の関係によって求められるものとします。もしZcとZsが同じであればP=1、それ以外の場合はP=10となることを意味しています。
これを先ほど求めたEを求める公式に掛け算します。これはペナルティPを以てしてもExpected Latency(E)が覆らないのであれば、ユーザビリティが向上することによって料金分を十分ペイできると判断しゾーン間通信を許容することを意味します。
これで、Eを求める公式は完成となります。
実装について
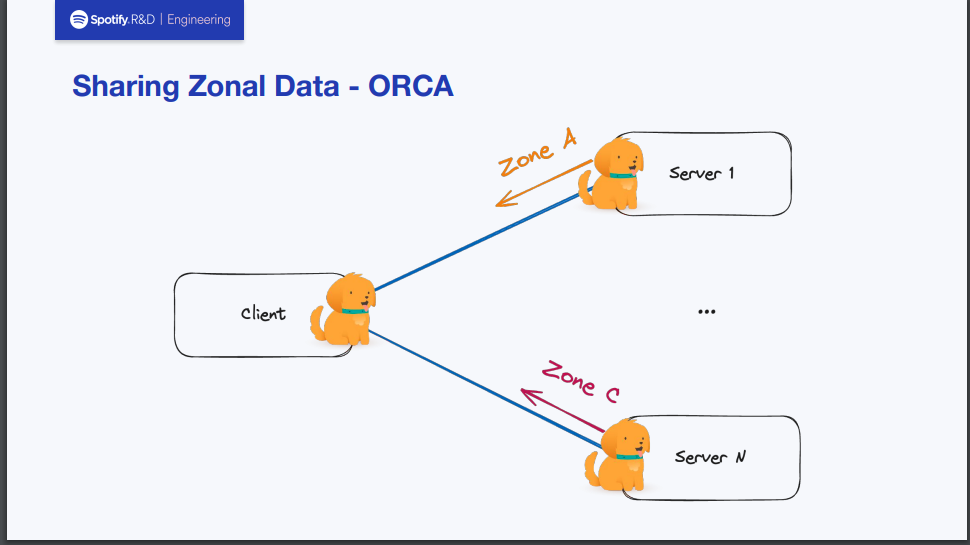
上記の公式のためのデータ収集は独自実装ではありますが、ORCA(Open Request Cost Aggrecation)を大いに参考にしたとのことでした。
ORCAはデータプレーンロードバランシングにフォーカスを当てた標準仕様とその実装です。 プロポーザルのスコープには以下2点が含まれます。
- バックエンドでのメトリクス集計メカニズム
- データプレーン上でこれらのレポートを集計
また、含まれないスコープとしては以下2点が挙げられています。
- 集約されたデータを操作するロードバランシングアルゴリズム
- ロードバランシングポリシーをデータプレーンに配信するメカニズム
具体的な内容についてはプロポーザルのご覧いただくこととし、ここでは割愛します。
Spotify社のバックエンドではJavaをメインで使用しており、gRPCライブラリにてORCAの実装がすでに進んでいました。 これを参考にして、自分たちのニーズに合うように実装しゾーンの情報などのデータ収集を進めていったとのことでした。
結果
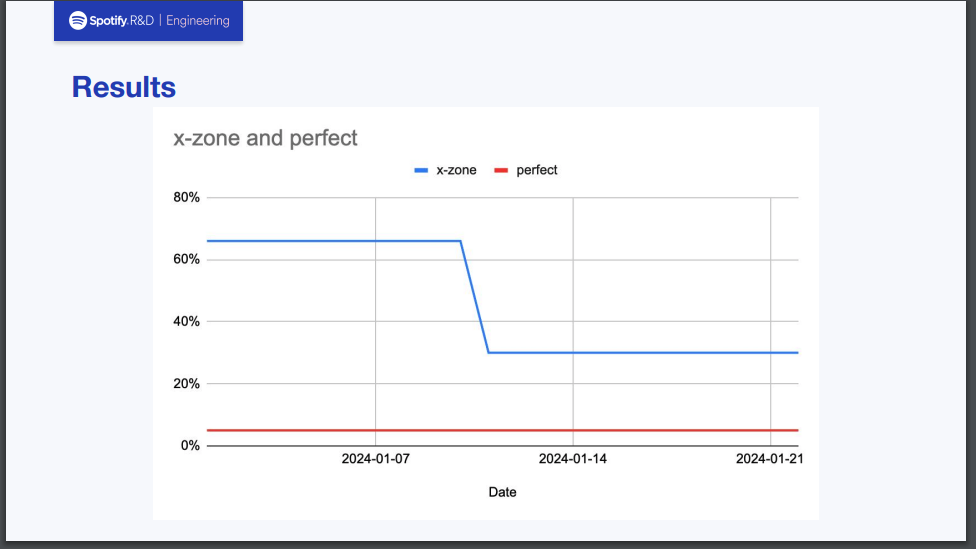
これらの実装を通して約70%あったゾーン間通信は約30%まで減ったとのことでした。
どこでも収集しているようなメトリクスと少しの工夫を交えた、これだけシンプルな仕組みでサービスに影響を与えずに十分な成果が得られたということを主張しており、「複雑そうな問題の解決策は意外にもシンプルなものだ」という言葉が私はとても印象に残っています。
終わりに
私自身も似たような課題に別のアプローチで取り組んだ経験があることや、エンジニアリングで自分が意識していることが「シンプルさで複雑な課題解決を行う」というものだったりするため印象に残るセッションでした。
質疑応答ではこのペナルティPの値はゾーンごとのサーバーの数を増減しつつ調整していったものの、10はかなり保守的な値でまずはここから始めてみたということをおっしゃっていました。しっかり安全性を担保することを意識しつつ、完璧ではなく十分を繰り返して改善していくことを目指したとのことで、これもとても大切な思考だと思いました。